Abstract
Approaches for single-view reconstruction typically rely on viewpoint annotations, silhouettes, the absence of background, multiple views of the same instance, a template shape, or symmetry. We avoid all such supervision and assumptions by explicitly leveraging the consistency between images of different object instances. As a result, our method can learn from large collections of unlabelled images depicting the same object category. Our main contributions are two ways for leveraging cross-instance consistency: (i) progressive conditioning, a training strategy to gradually specialize the model from category to instances in a curriculum learning fashion; and (ii) neighbor reconstruction, a loss enforcing consistency between instances having similar shape or texture. Also critical to the success of our method are: our structured autoencoding architecture decomposing an image into explicit shape, texture, pose, and background; an adapted formulation of differential rendering; and a new optimization scheme alternating between 3D and pose learning. We compare our approach, UNICORN, both on the diverse synthetic ShapeNet dataset - the classical benchmark for methods requiring multiple views as supervision - and on standard real-image benchmarks (Pascal3D+ Car, CUB) for which most methods require known templates and silhouette annotations. We also showcase applicability to more challenging real-world collections (CompCars, LSUN), where silhouettes are not available and images are not cropped around the object.
Overview video (4min)
UNICORN 🦄 - UNsupervised Instance COnsistency for 3D ReconstructioN
1. Structured autoencoding
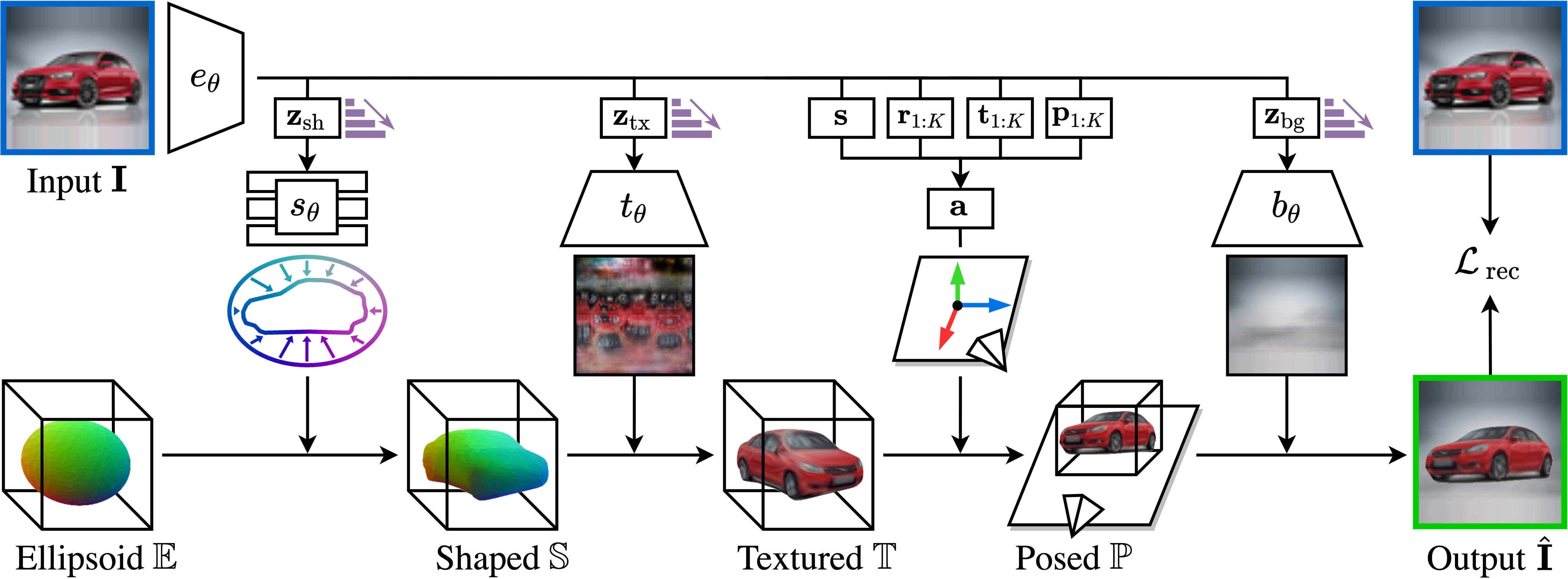
Overview. Given an input image, we
predict parameters that are decoded into 4 explicit factors (shape, texture, pose, background)
and composed to generate the output image. Progressive conditioning is
represented with ![]() .
.
2. Cross-instance consistency
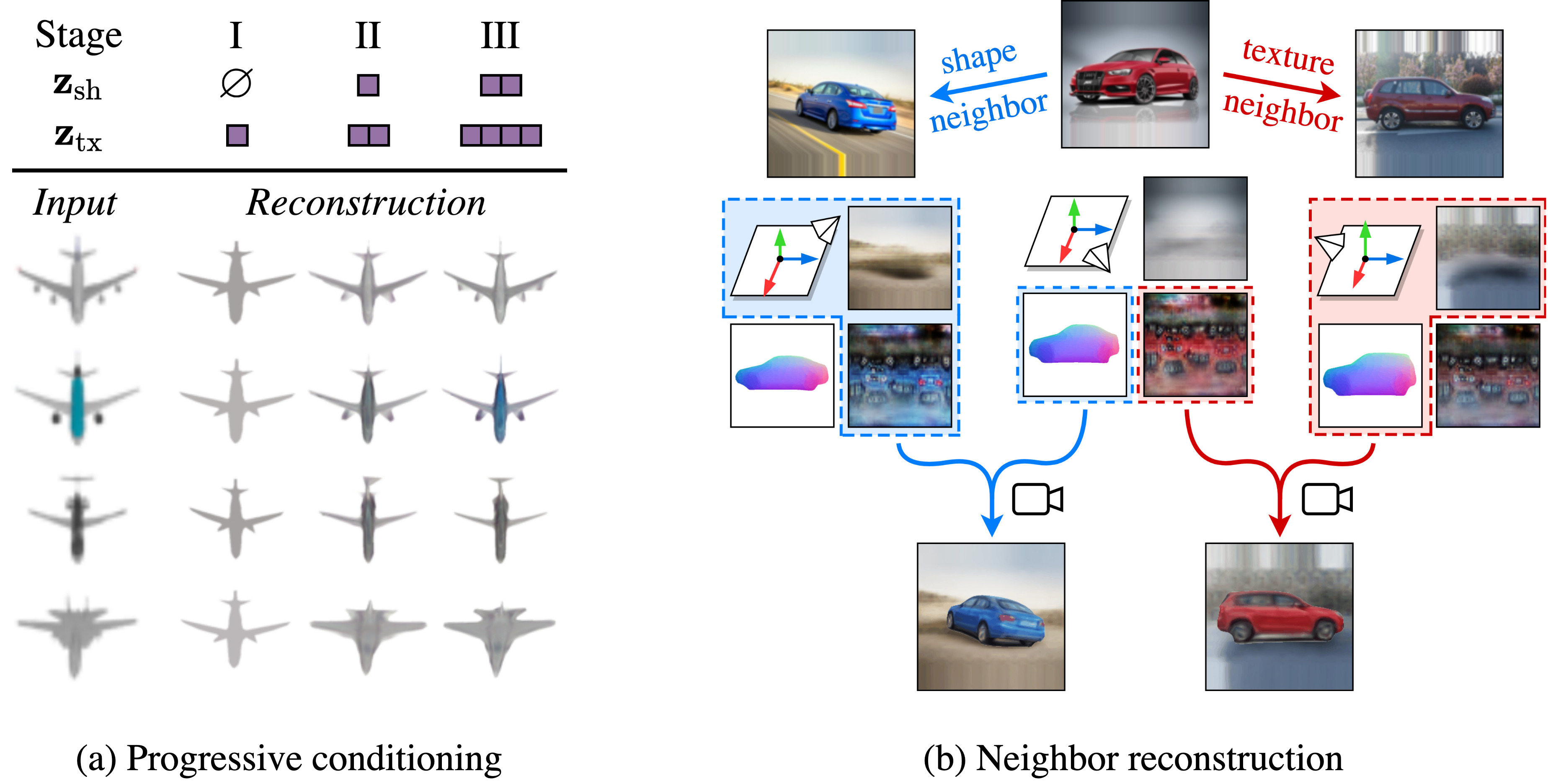
We leverage cross-instance consistency to avoid degenerate solutions. (a) Progressive conditioning amounts to gradually increasing the size of the conditioning latent spaces, here associated to shape and texture. (b) We explicitly share the shapes and textures across neighboring instances by swapping characteristics and applying a loss to associated neighbor reconstructions.
Results - 3D reconstruction from a single image
Results - Segmentation and correspondences
CompCars

CUB

LSUN Moto

Resources
Paper

Code
Slides

BibTeX
If you find this work useful for your research, please cite:
@inproceedings{monnier2022unicorn,
title={{Share With Thy Neighbors: Single-View Reconstruction by Cross-Instance Consistency}},
author={Monnier, Tom and Fisher, Matthew and Efros, Alexei A. and Aubry, Mathieu},
booktitle={{ECCV}},
year={2022},
}
Further information
If you like this project, check out related works from our group:
- Loiseau et al. - Representing Shape Collections with Alignment-Aware Linear Models (3DV 2021)
- Monnier et al. - Unsupervised Layered Image Decomposition into Object Prototypes (ICCV 2021)
- Monnier et al. - Deep Transformation-Invariant Clustering (NeurIPS 2020)
- Deprelle et al. - Learning elementary structures for 3D shape generation and matching (NeurIPS 2019)
- Groueix et al. - AtlasNet: A Papier-Mache Approach to Learning 3D Surface Generation (CVPR 2018)
Acknowledgements
We thank François Darmon for inspiring discussions; Robin Champenois, Romain Loiseau, Elliot Vincent for feedback on the manuscript ; Michael Niemeyer, Shubham Goel for details on the evaluation. This work was supported in part by ANR project EnHerit ANR-17-CE23-0008, project Rapid Tabasco, gifts from Adobe and HPC resources from GENCI-IDRIS (2021-AD011011697R1).