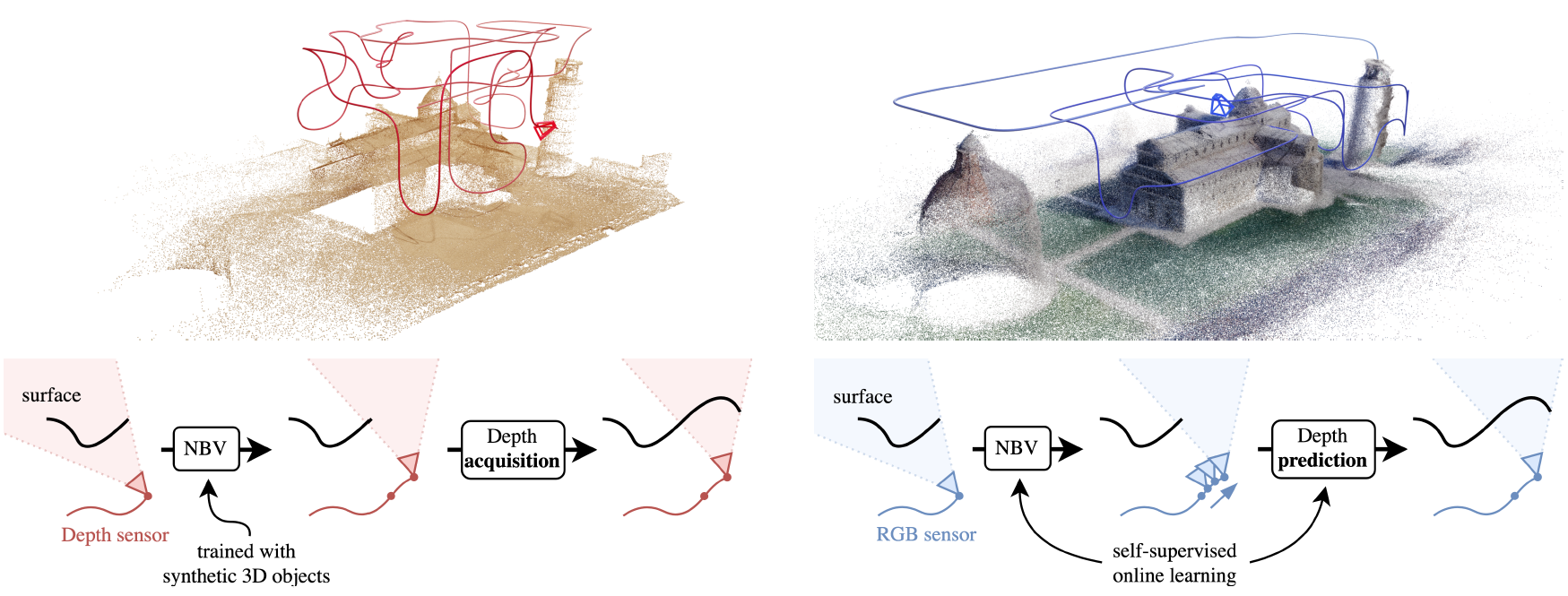
(a) NBV methods with a depth sensor (e.g., SCONE by Guédon et al.)
(b) Our approach MACARONS with an RGB sensor
(a) NBV methods with a depth sensor (e.g., SCONE by Guédon et al.)
(b) Our approach MACARONS with an RGB sensor
We introduce a method that simultaneously learns to explore new large
environments and to reconstruct them in 3D from color images
in a self-supervised fashion.
This is closely related to the Next Best View problem (NBV), where one
has to identify where to move the camera next to improve the coverage of an
unknown scene. However, most of the current NBV methods rely on depth sensors,
need 3D supervision and/or do not scale to large scenes.
In this paper, we propose the first deep-learning-based NBV approach for dense
reconstruction of large 3D scenes from RGB images. We call this approach
MACARONS, for Mapping And Coverage Anticipation with RGB Online
Self-Supervision. Moreover, we provide a dedicated training procedure for
online learning for scene mapping and automated exploration based on
coverage optimization in any kind of environment, with no explicit 3D
supervision. Consequently, our approach is also the first NBV method to
learn in real-time to reconstruct and explore arbitrarily large scenes in a
self-supervised fashion.
Indeed, MACARONS simultaneously learns to predict a "volume occupancy
field" from color images and, from this field, to predict the NBV.
We experimentally show that this greatly improves results for NBV exploration
of 3D scenes. In particular, we demonstrate this on a recent dataset
made of various 3D scenes and show it performs even better than recent methods
requiring a depth sensor, which is not a realistic assumption for outdoor
scenes captured with a flying drone. It makes our approach suitable for
real-life applications on small drones with a simple color camera.
More fundamentally, it shows that an autonomous system can learn to explore and
reconstruct environments without any 3D information a priori.
This video illustrates how MACARONS explores and reconstructs efficiently a
subset of three large 3D scenes.
In particular, the video shows several key-elements of our approach:
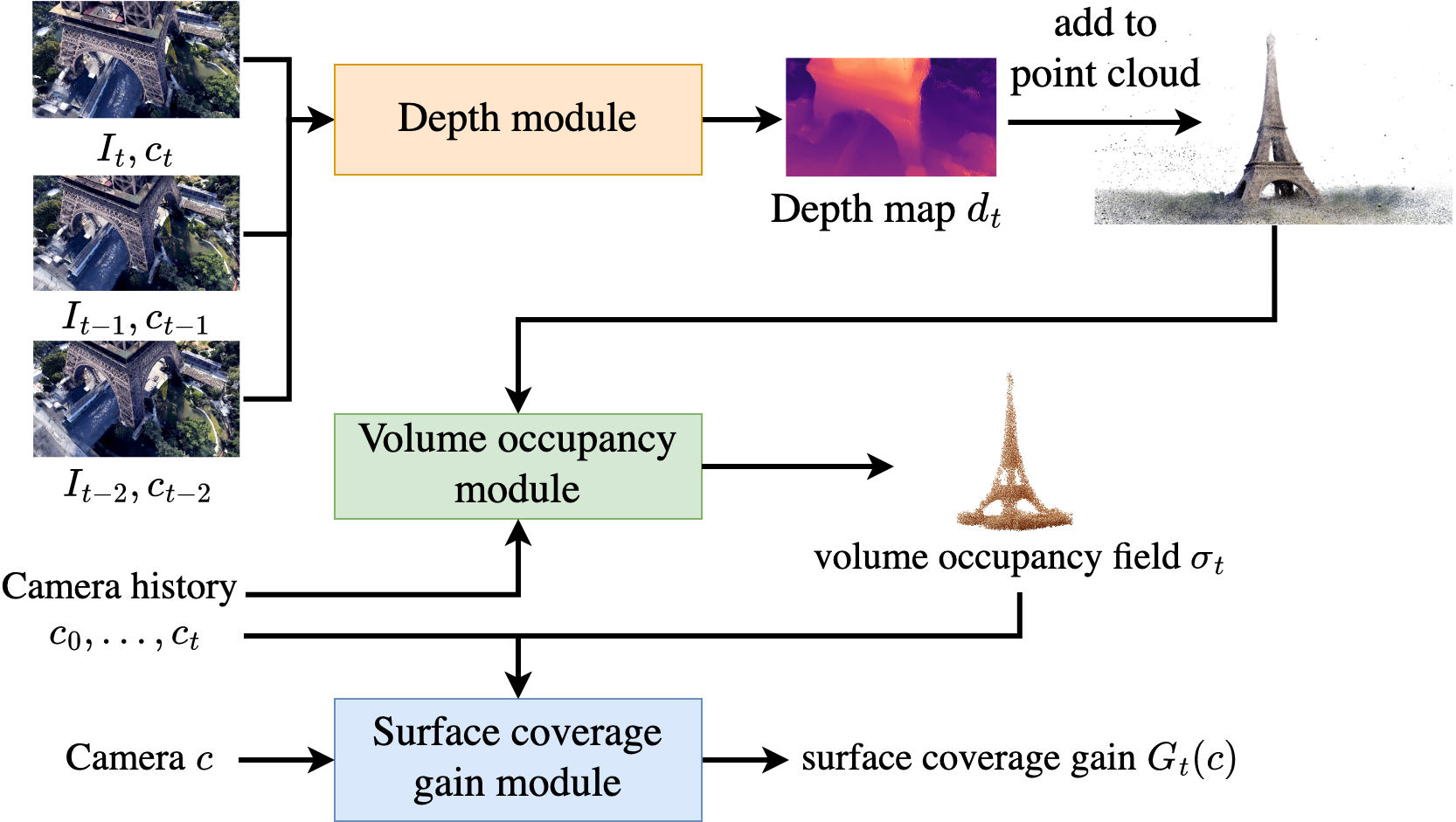
MACARONS simultaneously reconstructs the scene and selects the next best camera pose by running three neural modules:
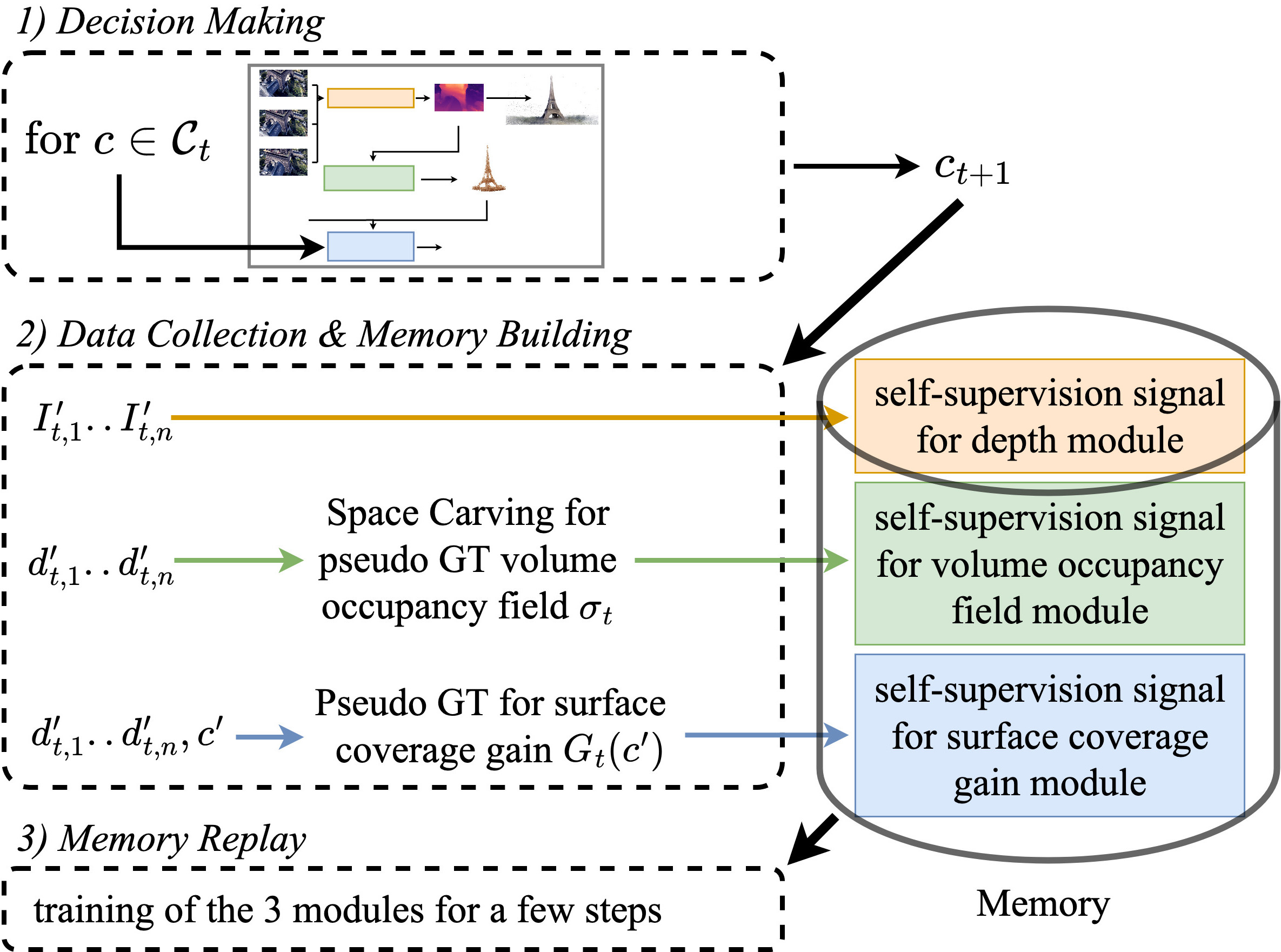
During online exploration, we perform a training iteration at each time step t which consists in three steps.

@inproceedings{guedon2023macarons,
title={MACARONS: Mapping And Coverage Anticipation with RGB Online Self-Supervision},
author={Gu{\'e}don, Antoine and Monnier, Tom and Monasse, Pascal and Lepetit, Vincent},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={940--951},
year={2023}
}
This work was granted access to the HPC resources of IDRIS under the allocation 2022-AD011013387 made by GENCI.
We thank Elliot Vincent for inspiring discussions and valuable feedback on the manuscript.
The template webpage is inspired from the (awesome) work UNICORN (ECCV 2022) by Monnier et al.
© You are welcome to copy the code, please attribute the source with a link
back to this page and the UNICORN webpage by Tom Monnier and remove
the analytics.
Possible misspellings: tom monier, tom monnie,
tom monie, monniert.
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
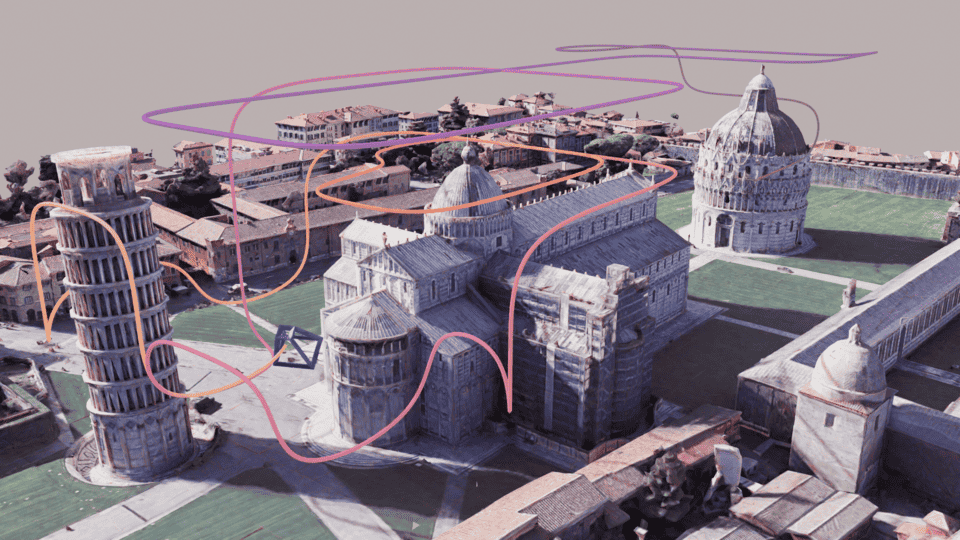 Trajectory in GT scene
Trajectory in GT scene
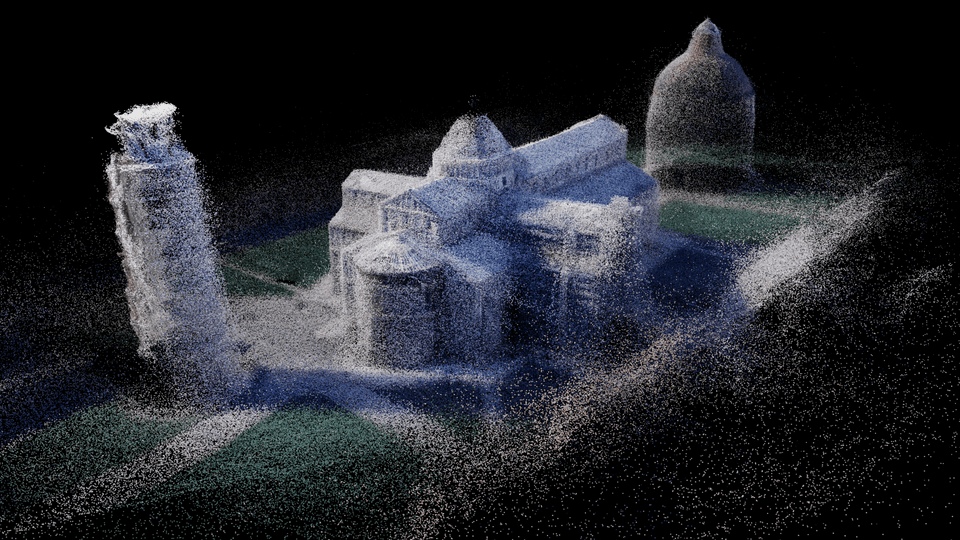 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
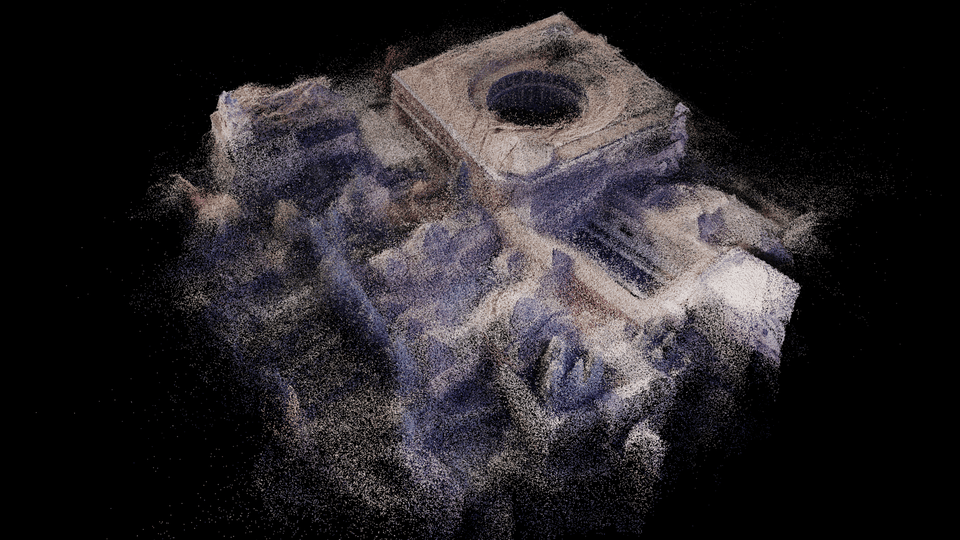 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
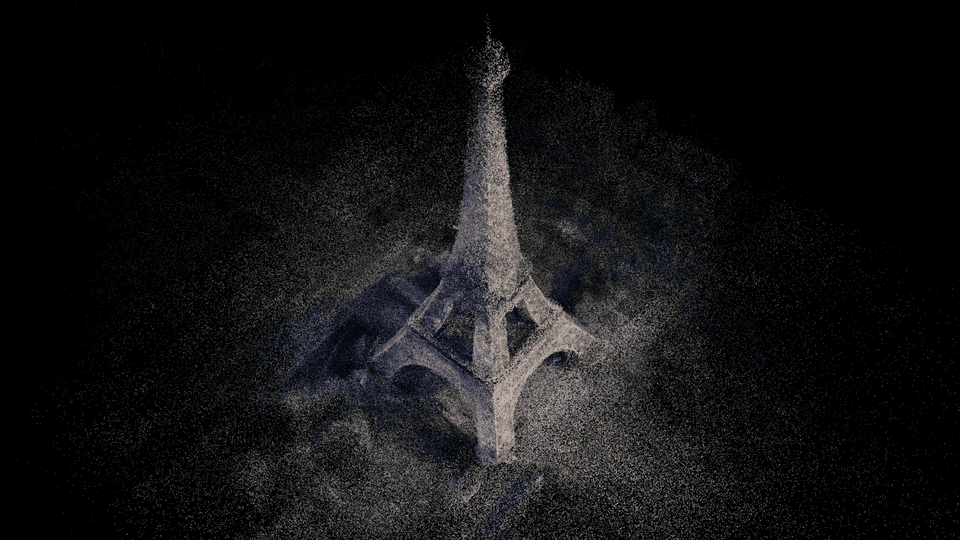 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
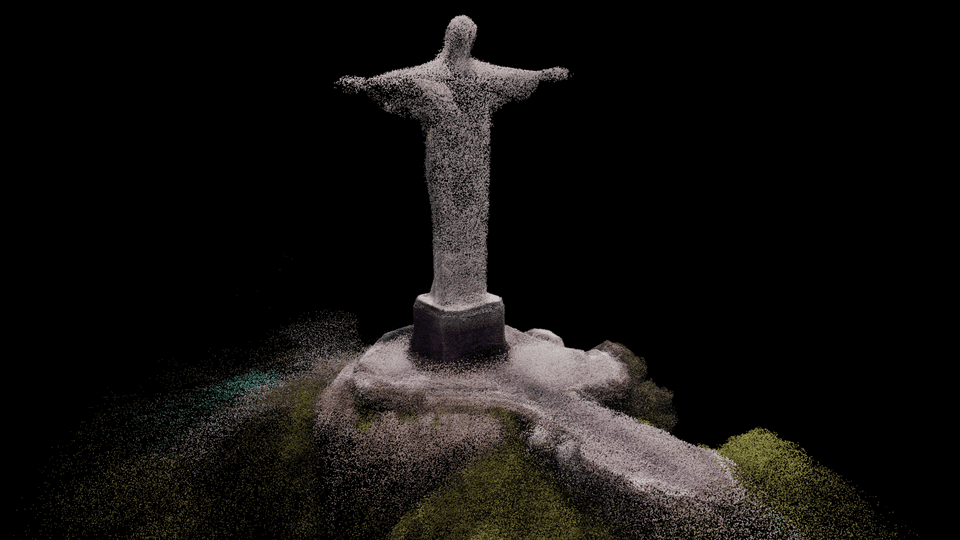 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
 Reconstructed surface
Reconstructed surface
 Trajectory in GT scene
Trajectory in GT scene
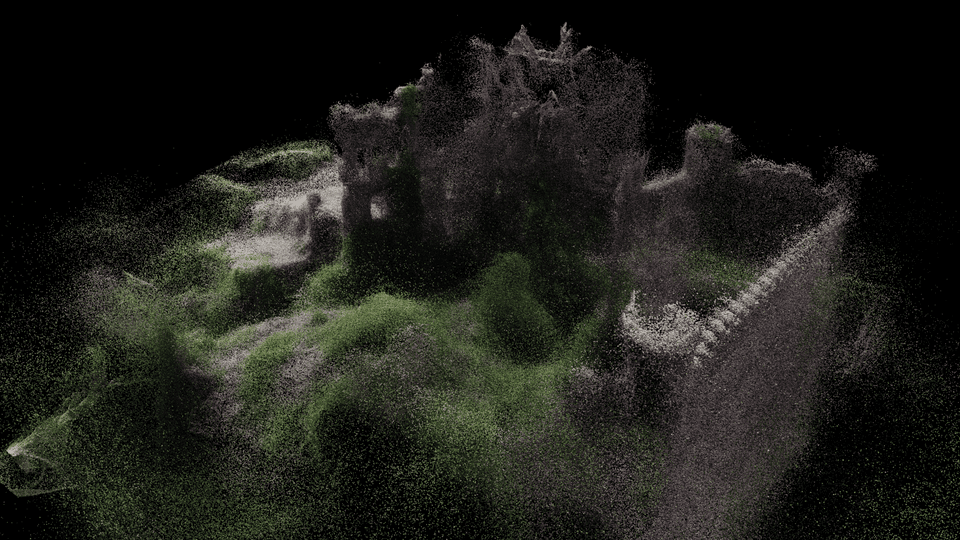 Reconstructed surface
Reconstructed surface