TL;DR
For the first time, we quantify the compute and environmental impacts of the entire research process of a GenAI model, from initial experimentation to final training, and including development, debbuging, evaluation, ablations, failed runs, and more.
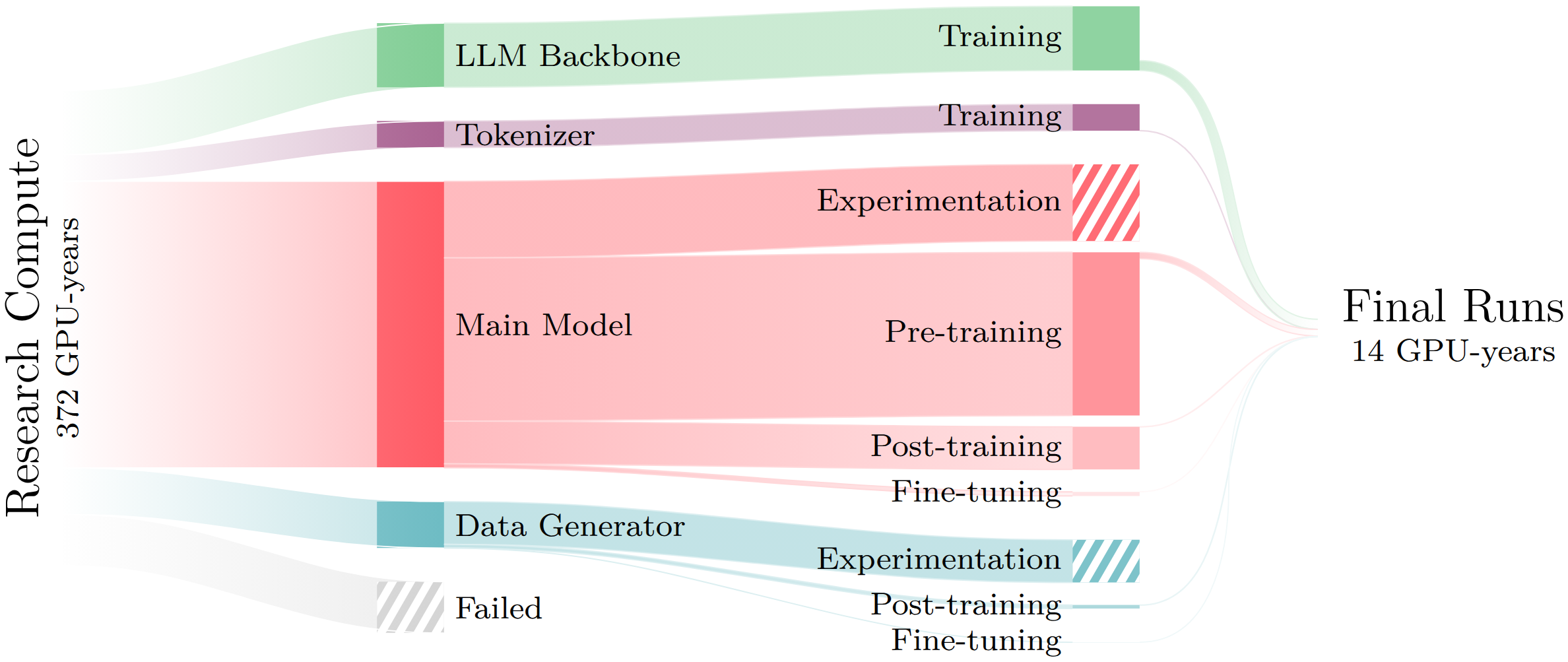
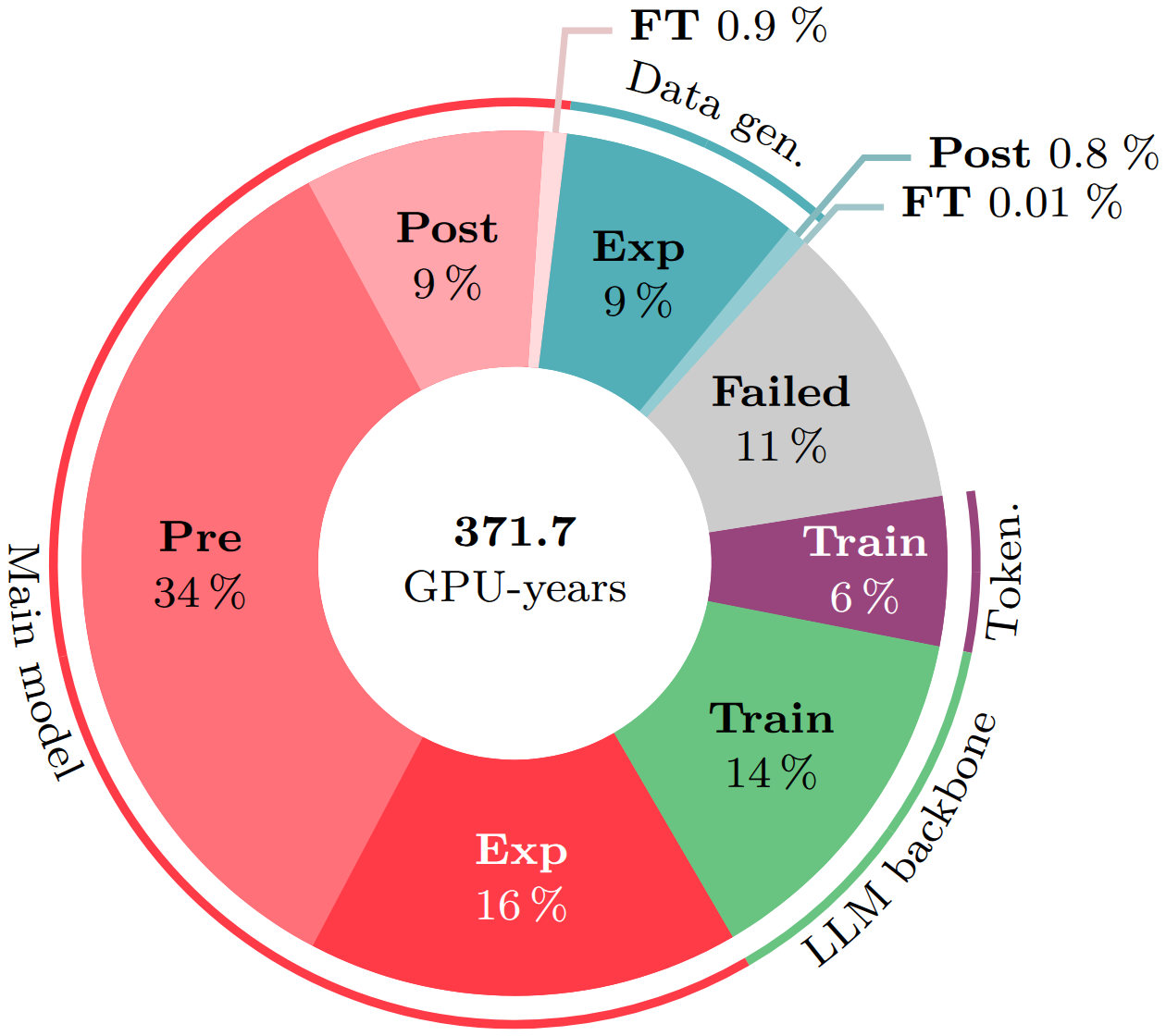
Creating the Moshi speech-text foundation model required 372 GPU-years of research and development compute. Only 4% of this compute corresponds to training the final version of each component (LLM backbone, tokenizer, main model, and data generator), the rest being devoted to early experimental versions, hyperparameter search, ablation studies, failed training runs, and more.
Abstract
New multi-modal large language models (MLLMs) are continuously being trained and deployed, following rapid development cycles. This generative AI frenzy is driving steady increases in energy consumption, greenhouse gas emissions, and a plethora of other environmental impacts linked to datacenter construction and hardware manufacturing. Mitigating the environmental consequences of GenAI remains challenging due to an overall lack of transparency by the main actors in the field. Even when the environmental impacts of specific models are mentioned, they are typically restricted to the carbon footprint of the final training run, omitting the research and development stages. In this work, we explore the impact of GenAI research through a fine-grained analysis of the compute spent to create Moshi, a 7B-parameter speech-text foundation model for real-time dialogue developed by Kyutai, a leading privately funded open science AI lab. For the first time, our study dives into the anatomy of compute-intensive MLLM research, quantifying the GPU-time invested in specific model components and training phases, as well as early experimental stages, failed training runs, debugging, and ablation studies. Additionally, we assess the environmental impacts of creating Moshi from beginning to end using a life cycle assessment methodology: we quantify energy and water consumption, greenhouse gas emissions, and mineral resource depletion associated with the production and use of datacenter hardware. Our detailed analysis allows us to provide actionable guidelines to reduce compute usage and environmental impacts of MLLM research, paving the way for more sustainable AI research.
Takeaways
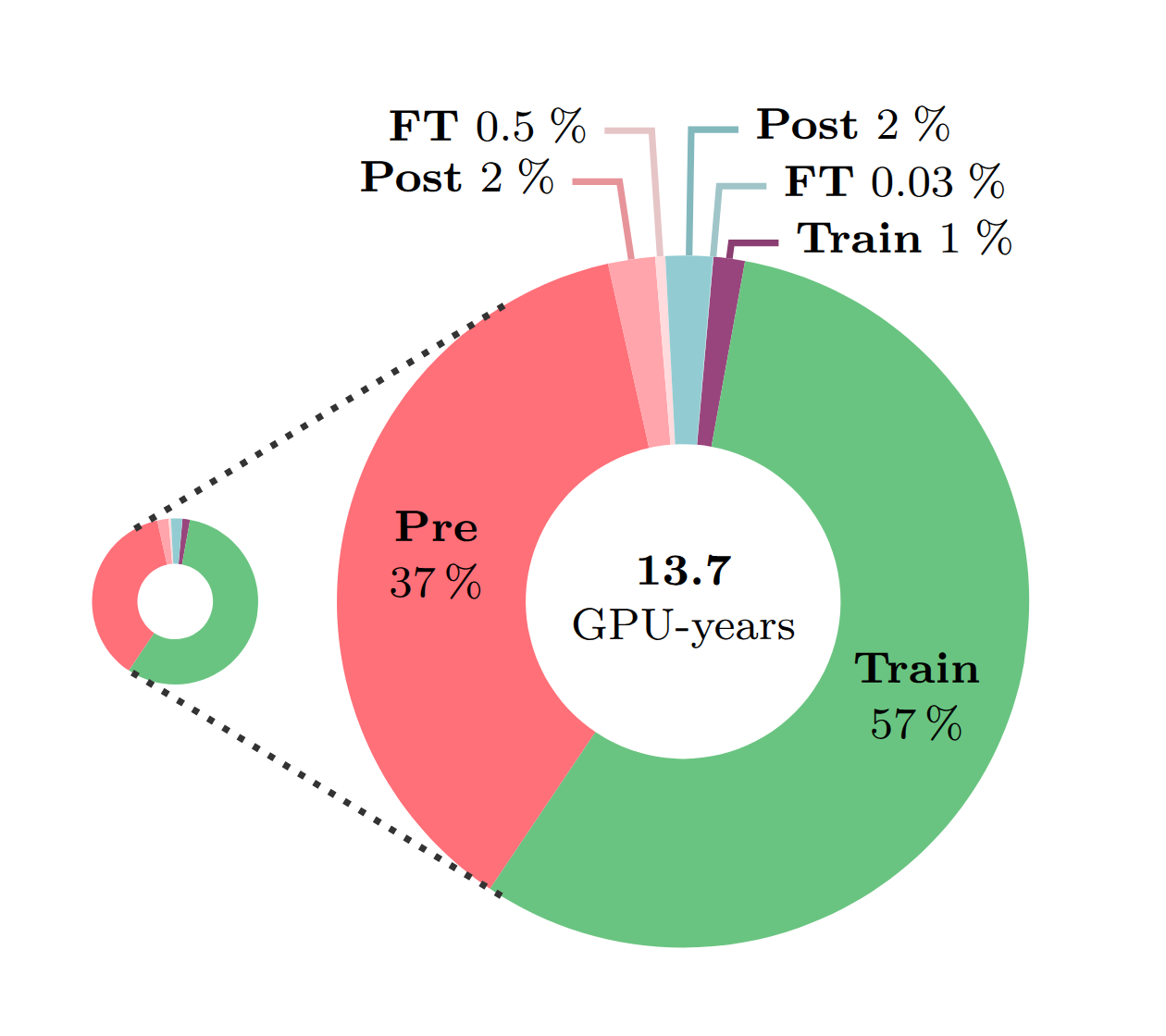
- Final model training represents 4% of the total research and development budget.
- Debugging and failed runs together account for more than 13% of total compute.
- Experimentation on novel elements represents 25% of the compute.
- Standard modules have proportionally lower research costs compared to innovative modules.
- 13% of the training runs account for nearly 90% of total compute.
Environmental Assessment
- The energy consumption of 727 people in a year in France.
- The global warming potential of 39 people in a year in France.
- The water consumption of 342 people in a year in France.
- The mineral and metal depletion potential of 6,566 smartphones, or 483 laptops.
Results
Research vs. final training compute
We compare the compute required for the full research and development process of Moshi to the compute of training a single final version of each module. We distribute the compute by model component: LLM backbone, tokenizer, main model, data generator; and training phase: experimentation (Exp), pre-training (Pre), post-training (Post), fine-tuning (FT).
BibTeX
@misc{lopez-rauhutEnvironmentalFootprintGenAI2026,
title = {Environmental Footprint of {{GenAI}} Research: {{Insights}} from the {{Moshi}} Foundation Model},
author = {{L{\'o}pez-Rauhut}, Marta and Landrieu, Loic and Aubry, Mathieu and Ligozat, Anne-Laure},
year = 2026,
month = apr,
journal = {arXiv.org},
doi = {10.48550/arXiv.2604.11154},
}Acknowledgments
This work was supported by the ANR project SHARP ANR-23-PEIA-0008 in the context of the PEPR IA.
The authors would like to thank the Kyutai team for sharing exhaustively their data, a testimony to their commitment to open science and their rare openness to consider and question the impacts of research. We are especially grateful to Alexandre Défossez, who made this work possible by extracting all the necessary data and very kindly and patiently answered our questions regarding their interpretation. We are also grateful to Patrick Pérez, who drives Kyutai's vision and made this work possible, and Edouard Grave, who provided the figures regarding the Helium LLM.
The authors would also like to thank their colleagues at the IMAGINE and LISN labs, who provided valuable feedback on initial versions of the manuscript and showed great interest in the outcome of this work.