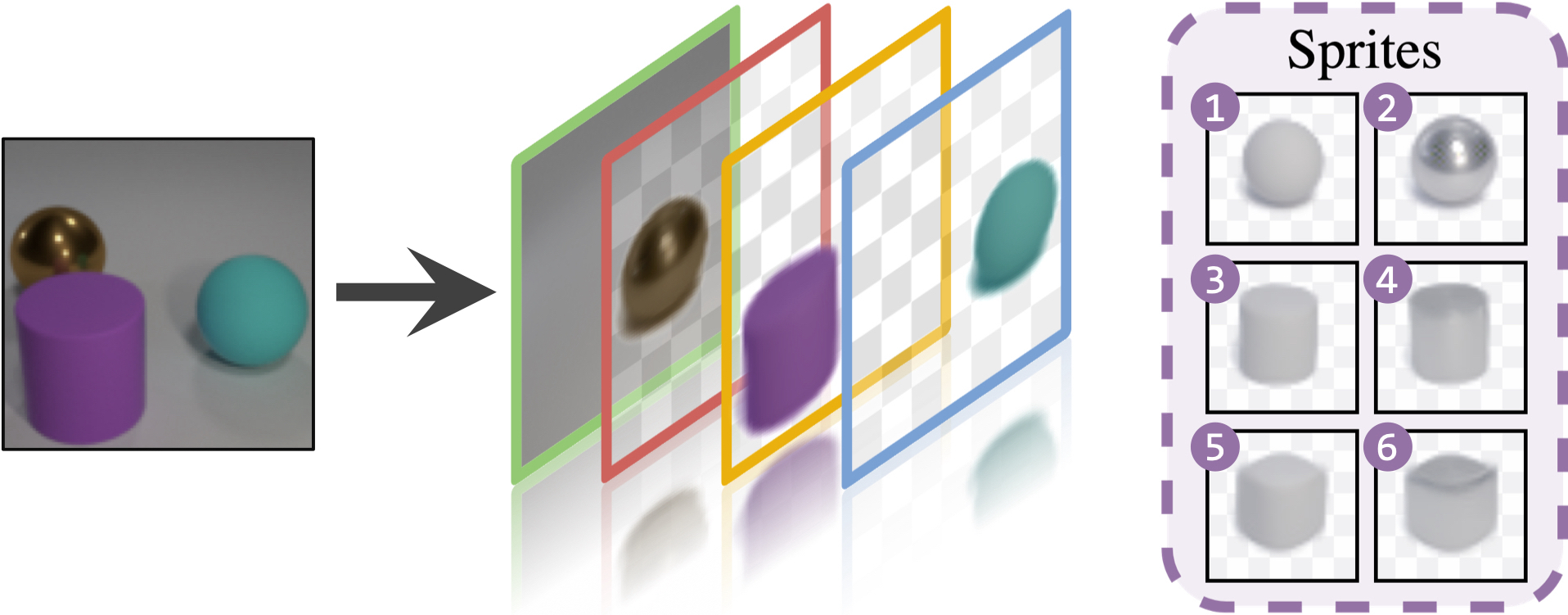
We present an unsupervised learning framework for decomposing images into layers of automatically discovered object models. Contrary to recent approaches that model image layers with autoencoder networks, we represent them as explicit transformations of a small set of prototypical images. Our model has three main components: (i) a set of object prototypes in the form of learnable images with a transparency channel, which we refer to as sprites; (ii) differentiable parametric functions predicting occlusions and transformation parameters necessary to instantiate the sprites in a given image; (iii) a layered image formation model with occlusion for compositing these instances into complete images including background. By jointly learning the sprites and occlusion/transformation predictors to reconstruct images, our approach not only yields accurate layered image decompositions, but also identifies object categories and instance parameters. We first validate our approach by providing results on par with the state of the art on standard multi-object synthetic benchmarks (Tetrominoes, Multi-dSprites, CLEVR6). We then demonstrate the applicability of our model to real images in tasks that include clustering (SVHN, GTSRB), cosegmentation (Weizmann Horse) and object discovery from unfiltered social network images. To the best of our knowledge, this is the first time that a layered image decomposition algorithm learns an explicit and shared concept of objects, and is robust enough to be applied to real images.
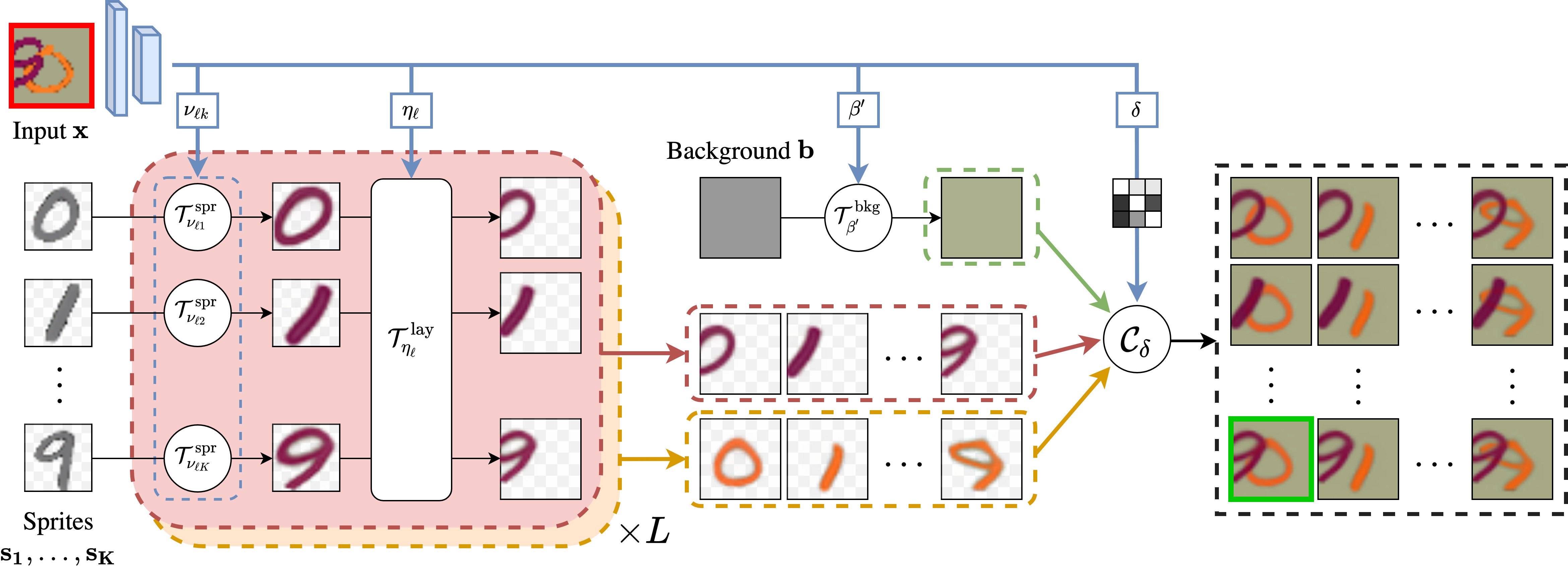
Overview. Given an input image
(highlighted in red), we predict
for each layer
the transformations
and
to apply to the set of sprites
that best reconstruct the input. Transformed
sprites and transformed background can be composed through
into many possible reconstructions given a predicted occlusion matrix
. We introduce a greedy algorithm
to select the best reconstruction (highlighted in green).


Multi-object segmentations. From left to right, we show inputs, reconstructions, semantic segmentation, instance segmentation, and first decomposition layers. We urge the visitors to click HERE for other random decompositions.
Weizamnn Horse database co-segmentation. We show result examples giving for each input, its reconstruction, the layered decomposition (background, foreground, mask) as well as the extracted foreground.

Image manipulation. Given an input image from CLEVR6 (top left), we show several image manipulations. On the bottom left, we modify the scale, and from top to bottom on the right, we use different sprites, vary their positions and change their colors.


@inproceedings{monnier2021dtisprites,
title={{Unsupervised Layered Image Decomposition into Object Prototypes}},
author={Monnier, Tom and Vincent, Elliot and Ponce, Jean and Aubry, Mathieu},
booktitle={ICCV},
year={2021},
}
We thank François Darmon, Hugo Germain and David Picard for valuable feedback. This work was supported in part by: the French government under management of Agence Nationale de la Recherche as part of the project EnHerit ANR-17-CE23-0008 and the "Investissements d'avenir" program, reference ANR-19-P3IA-0001 (PRAIRIE 3IA Institute); project Rapid Tabasco; gifts from Adobe; the Louis Vuitton/ENS Chair in Artificial Intelligence; the Inria/NYU collaboration; and HPC resources from GENCI-IDRIS (Grant 2020-AD011011697).
© You are welcome to copy this website's code for your personal use, please attribute the source with a link back to this page and remove the analytics code in the header. Possible misspellings: tom monier, tom monnie, tom monie, monniert.