Abstract
While foundation models drive steady progress in image segmentation and diffusion algorithms compose always more realistic images, the seemingly simple problem of identifying recurrent patterns in a collection of images remains very much open. In this paper, we focus on sprite-based image decomposition models, which have shown some promise for clustering and image decomposition and are appealing because of their high interpretability. These models come in different flavors, need to be tailored to specific datasets, and struggle to scale to images with many objects. We dive into the details of their design, identify their core components, and perform an extensive analysis on clustering benchmarks. We leverage this analysis to propose a deep sprite-based image decomposition method that performs on par with state-of-the-art unsupervised class-aware image segmentation methods on the standard CLEVR benchmark, scales linearly with the number of objects, identifies explicitly object categories, and fully models images in an easily interpretable way.
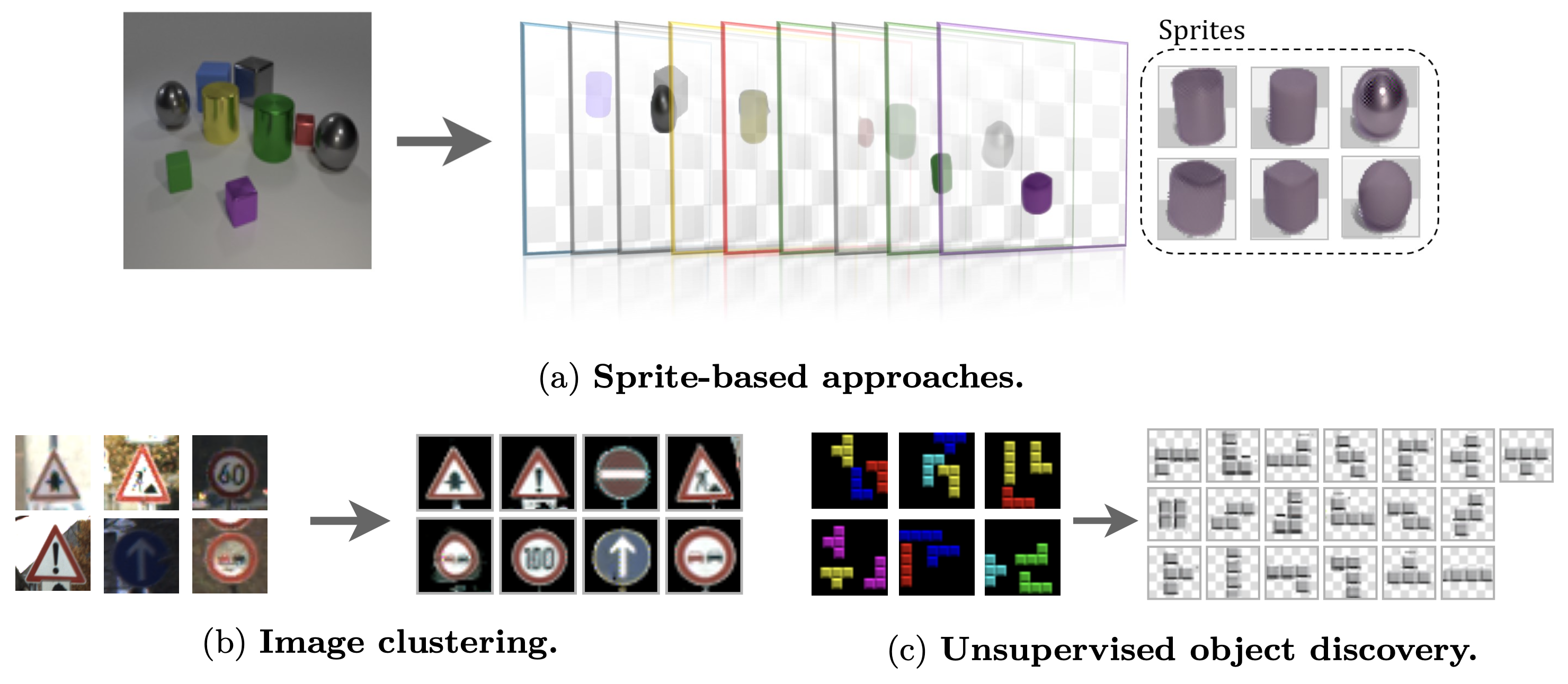
Overview

We decompose all sprite-based models in four main components: (1) a Sprite Generation Module that outputs $K$ sprites $S$, (2) a Transformation Module that takes as input an image $I$ and the sprites $S$ to predict transformed sprites $\bar{S}^I$, (3) a Decision Module that takes the image $I$ and transformed sprites $\bar{S}^I$ as input and outputs a probability distribution $p^I$ for using the sprites, and (4) a Training Criteria which consists of a reconstruction loss and potential regularization terms.
Design Choices
The Sprite Generation Module can learn the sprites $S$ directly as learnable parameters (Pixels), generate them from learnable latent variables $z$ with a multi-layer perceptron (MLP) or a UNet architecture.
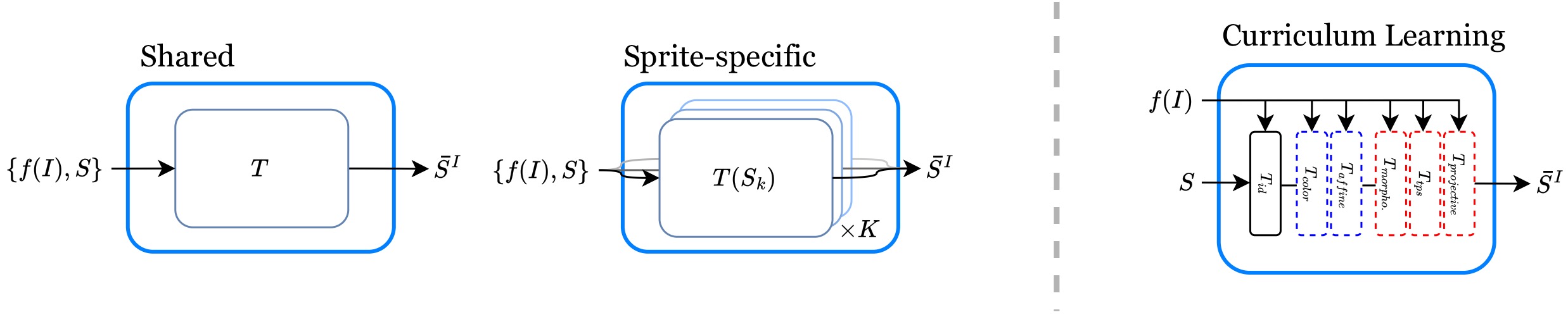
The Transformation Module parameters can be learned with a shared or sprite-specific network, and with different curriculum learning strategies.

The Decision Module can select sprites leading to the minimum reconstruction error (Min-Loss), or predict them using the sprites' latent representations $z$ (Weight Prediction), or directly a linear projection (Linear Mapping), with alternative activations.

The Composition Model and Training Criteria, where the main loss can either be the sum of the reconstruction errors obtained with all the possible sprites selection weighted by their probability ($\mathcal{L}_{0-1}$) or the reconstruction error with composite sprites ($\mathcal{L}_\text{comp}$). It can also include regularizations ($\mathcal{L}_\text{\{freq, bin, empty\}}$).
Key Findings
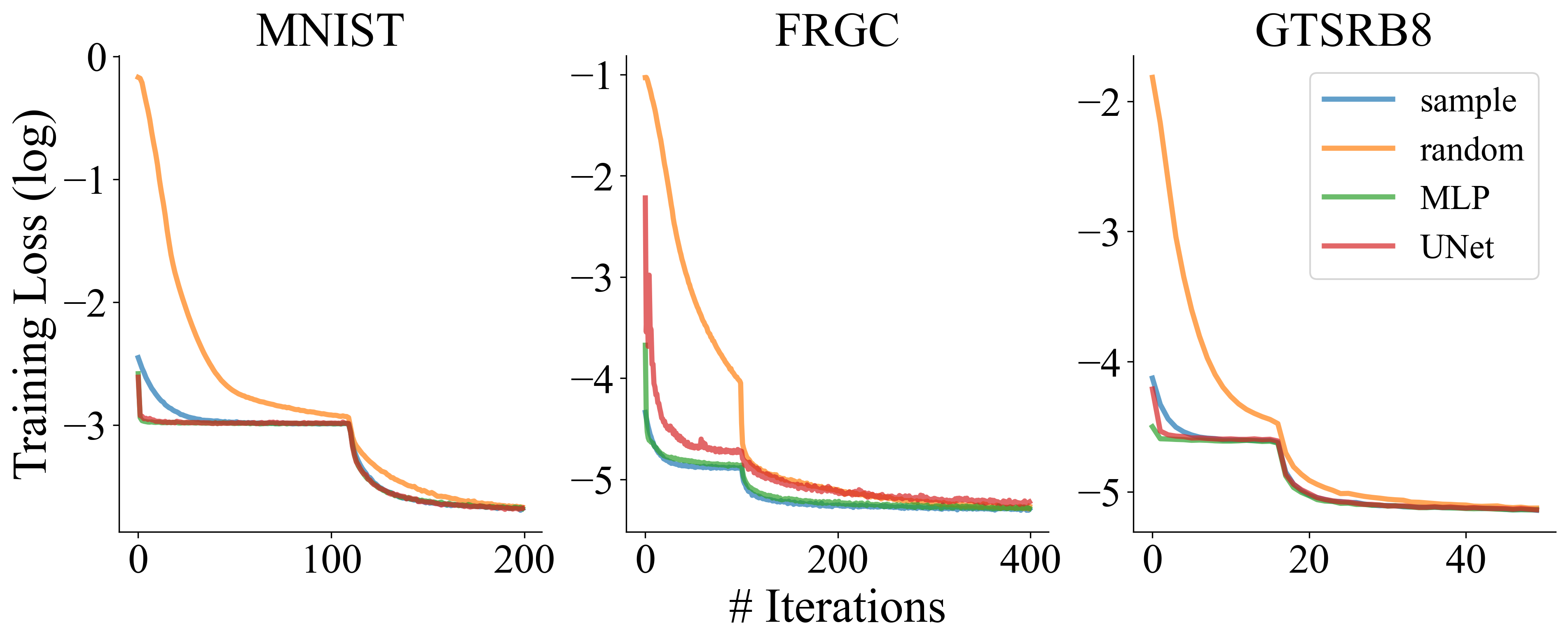
Convergence of sprite generation modules: Learning sprites with an MLP leads to slightly better results on average. Moreover, an analysis of the training loss curves shows that learning sprites through generator networks leads to clearly faster convergence.


Effects of sharing transformation modules: Sharing the transformations among sprites encourages them to be more uniform, e.g., have similar colors and spatial location.
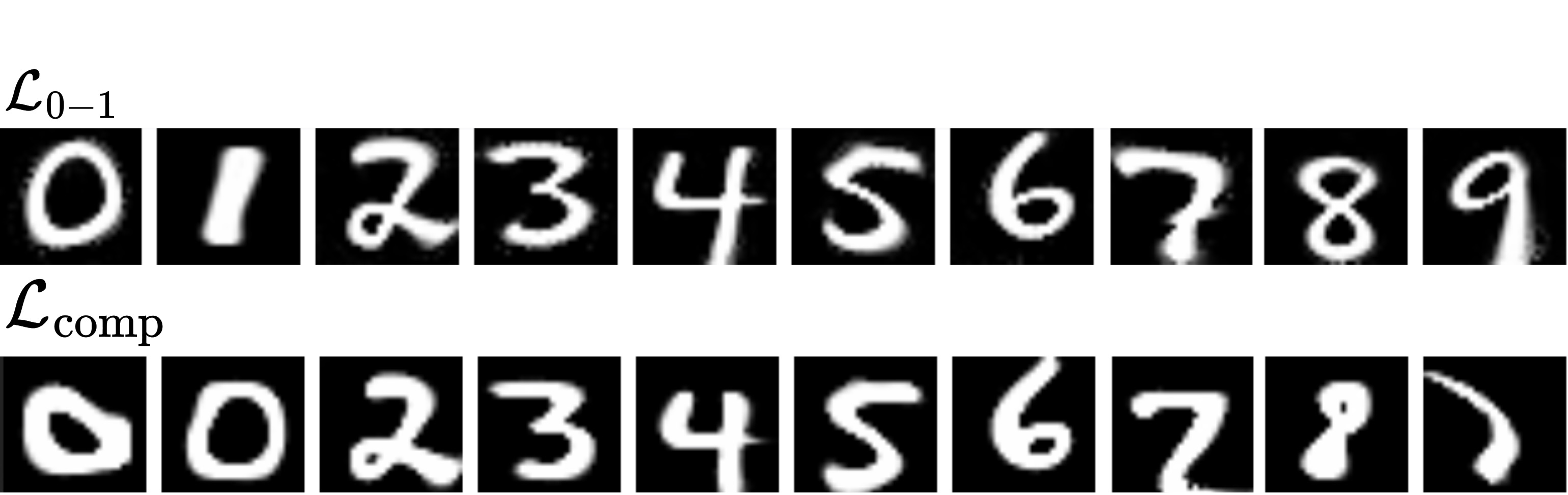

Qualitative effects of different criteria: Compared with weighting the reconstruction loss for each sprite ($\mathcal{L}_{0-1}$, top rows), weighting transformed sprites and composing to reconstruct ($\mathcal{L}_\text{comp}$, bottom rows) results in (a) sprites representing parts of the objects instead of the object itself and (b) sprites focusing on the distinct characteristics of a subject and using composition to model shading effects.

Time complexity: The time per iteration of sprite prediction with linear mapping scales linearly with the number of object layers in multi-layer image decomposition, while Min-Loss scales exponentially.
Results on CLEVR Benchmark

Figure: The three left columns show the sprites' appearances (Frg.), masks, and combination (Sprite), including the empty sprite, and the background. The other columns show for four different examples, the input image, its reconstruction, semantic segmentation (Sem. Seg.), instance segmentation (Ins. Seg.), background (Bkg. Layer), and the different transformed sprites (Object Layers).
| Method | class-aware | CLEVR | |||
|---|---|---|---|---|---|
| mIoU$^\dagger$ | ARI-FG$^\dagger$ | mAcc | avg-mIoU | ||
| MONet [Burgess et al. (2019)] | 30.7±14.9 | 54.5±11.4 | - | - | |
| IODINE [Greff et al. (2019)] | 45.1±17.9 | 93.8±0.8 | - | - | |
| SPAIR [Crawford & Pineau (2019)] | 66.0±4.0 | 77.1±1.9 | - | - | |
| GNM [Jiang & Ahn (2020)] | 59.9±3.7 | 65.1±4.2 | - | - | |
| Slot Attention [Locatello et al. (2020)] | 36.6±24.8 | 95.9±2.4 | - | - | |
| eMORL [Emami et al. (2021)] | 50.2±22.6 | 93.3±3.2 | - | - | |
| Genesis-V2 [Engelcke et al. (2021)] | 9.5±0.6 | 57.9±20.4 | - | - | |
| MarioNette [Smirnov et al. (2021)] | ✓ | 72.1±0.6 | 56.8±0.4 | 16.1±0.2 | 7.3±0.4 |
| AST-Seg-B3-CT [Sauvalle & de La Fortelle (2023)] | 90.3±0.2 | 98.3±0.1 | 20.8±1.2 | 12.1±0.2 | |
| DTI-Sprites [Monnier et al. (2021)] | ✓ | 54.5±1.2 | 93.2±2.0 | 69.8±4.5 | 55.7±6.0 |
| Ours-D | ✓ | 53.8±0.3 | 95.1±0.5 | 70.6±0.2 | 55.3±0.2 |
Table: Comparisons for instance segmentation with standard deviation over 3 runs. Sources for $\dagger$ (excluding Monnier et al. [2021]): Karazija et al. [2021] and Sauvalle et al. [2023].
BibTeX
@article{baltaci2026deep,
title = {Deep sprite-based image models: An analysis},
author = {Baltac{\i}, Zeynep Sonat and Loiseau, Romain and Aubry, Mathieu},
journal = {Transactions on Machine Learning Research},
year = {2026}
}
Acknowledgement
This work was funded by the ANR project VHS ANR-21-CE38-0008, and the ERC project DISCOVER funded by the European Union's Horizon Europe Research and Innovation program under grant agreement No. 101076028. This work was granted access to the HPC resources of IDRIS under the allocation AD011015415R1, AD011015415, and AD011014404 made by GENCI. We would like to thank Ioannis Siglidis for insightful discussions, and Robin Champenois and Ségolène Albouy for their contributions to the codebase.