ENPC, Inria
Inria
Inria
ENPC
Composed Image Retrieval (CoIR) has recently gained popularity as a task that considers both text and image queries together, to search for relevant images in a database. Most CoIR approaches require manually annotated datasets, comprising image-text-image triplets, where the text describes a modification from the query image to the target image. However, manual curation of CoIR triplets is expensive and prevents scalability. In this work, we instead propose a scalable automatic dataset creation methodology that generates triplets given video-caption pairs, while also expanding the scope of the task to include Composed Video Retrieval (CoVR). To this end, we mine paired videos with a similar caption from a large database, and leverage a large language model to generate the corresponding modification text. Applying this methodology to the extensive WebVid2M collection, we automatically construct our \ourWV dataset, resulting in 1.6 million triplets. Moreover, we introduce a new benchmark for CoVRwith a manually annotated evaluation set, along with baseline results. We further validate that our methodology is equally applicable to image-caption pairs, by generating 3.3 million CoIR training triplets using the Conceptual Captions dataset. Our model builds on BLIP-2 pretraining, adapting it to composed video (or image) retrieval, and incorporates an additional caption retrieval loss to exploit extra supervision beyond the triplet, which is possible since captions are readily available for our training data by design. We provide extensive ablations to analyze the design choices on our new CoVR benchmark. Our experiments also demonstrate that training a CoVR model on our datasets effectively transfers to CoIR, leading to improved state-of-the-art performance in the zero-shot setup on the CIRR, FashionIQ, and CIRCO benchmarks. Our code, datasets, and models are publicly available.
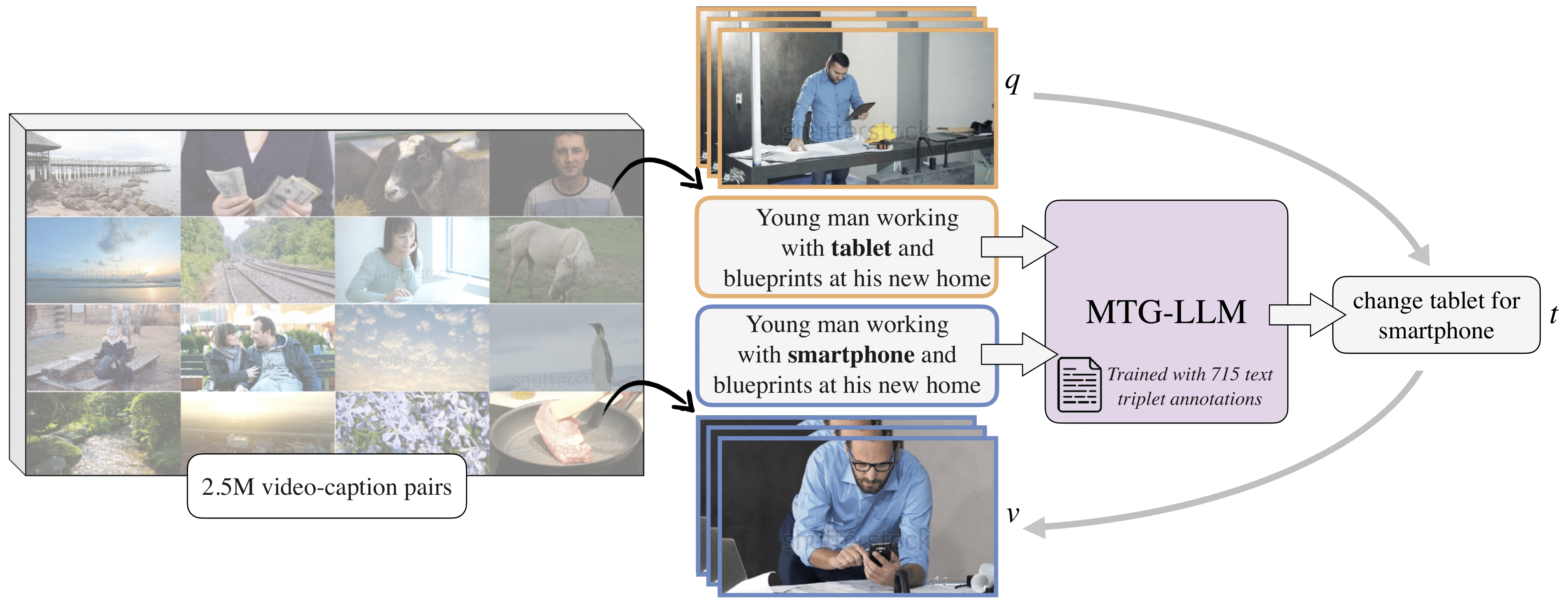
We automatically mine similar caption pairs from a large video-caption database from the Web, and use our modification text generation language model (MTG-LLM) to describe the difference between the two captions. MTG-LLM is trained on a dataset of 715 triplet text annotations. The resulting triplet of two corresponding videos (query \(q\) and target video \(v\)) and the modification text \(t\) is therefore obtained fully automatically, allowing a scalable CoVR training data generation.
Please contact us
(
,
)
if you would like to request the removal of any content, as well as to flag inappropriate content.
The dataset datasheet can be downloaded here.

The middle frame of each video is shown with its corresponding caption, with the distinct word highlighted in bold. Additionally, the generated modification text is displayed on top of each pair of videos.
@InProceedings{ventura24covr,
title = {{CoVR}: Learning Composed Video Retrieval from Web Video Captions},
author = {Lucas Ventura and Antoine Yang and Cordelia Schmid and G{\"u}l Varol},
booktitle = {AAAI},
year = {2024}
}
@article{ventura24covr2,
title = {{CoVR-2}: Automatic Data Construction for Composed Video Retrieval},
author = {Lucas Ventura and Antoine Yang and Cordelia Schmid and G{\"u}l Varol},
journal = {IEEE TPAMI},
year = {2024}
}
This work was granted access to the HPC resources of IDRIS under the allocation 2023-AD011014223 made by GENCI. The authors would like to acknowledge the research gift from Google, the ANR project CorVis ANR-21-CE23-0003-01, Antoine Yang's Google PhD fellowship, and thank Mathis Petrovich, Nicolas Dufour, Charles Raude, and Andrea Blazquez for their helpful feedback.
