

Abstract
The quality and generality of deep image features is crucially determined by the data they have been trained on, but little is known about this often overlooked effect. In this paper, we systematically study the effect of variations in the training data by evaluating deep features trained on different image sets in a few-shot classification setting. The experimental protocol we define allows to explore key practical questions. What is the influence of the similarity between base and test classes? Given a fixed annotation budget, what is the optimal trade-off between the number of images per class and the number of classes? Given a fixed dataset, can features be improved by splitting or combining different classes? Should simple or diverse classes be annotated? In a wide range of experiments, we provide clear answers to these questions on the miniImageNet, ImageNet and CUB-200 benchmarks. We also show how the base dataset design can improve performance in few-shot classification more drastically than replacing a simple baseline by an advanced state of the art algorithm.
Keywords: Dataset labeling, few-shot classification, meta-learning, weakly-supervised learning.1 minute summary video
Goal
Evaluate the impact of training dataset labeling and diversity on the few-shot classification performance of obtained features.

Figure 1: How should we design the base training dataset and how will it influence the features? a) Many classes with few examples / few classes with many examples; b) Simple or diverse base training images.
Few-shot classification as feature evaluation
- Training
- Use L2-normalized features during training (cosine classifier)
- no episodic training
-
Evaluation
- Few-shot classification
- Associate each test image to the novel class for which its average cosine similarity with the examples from this novel class is the highest
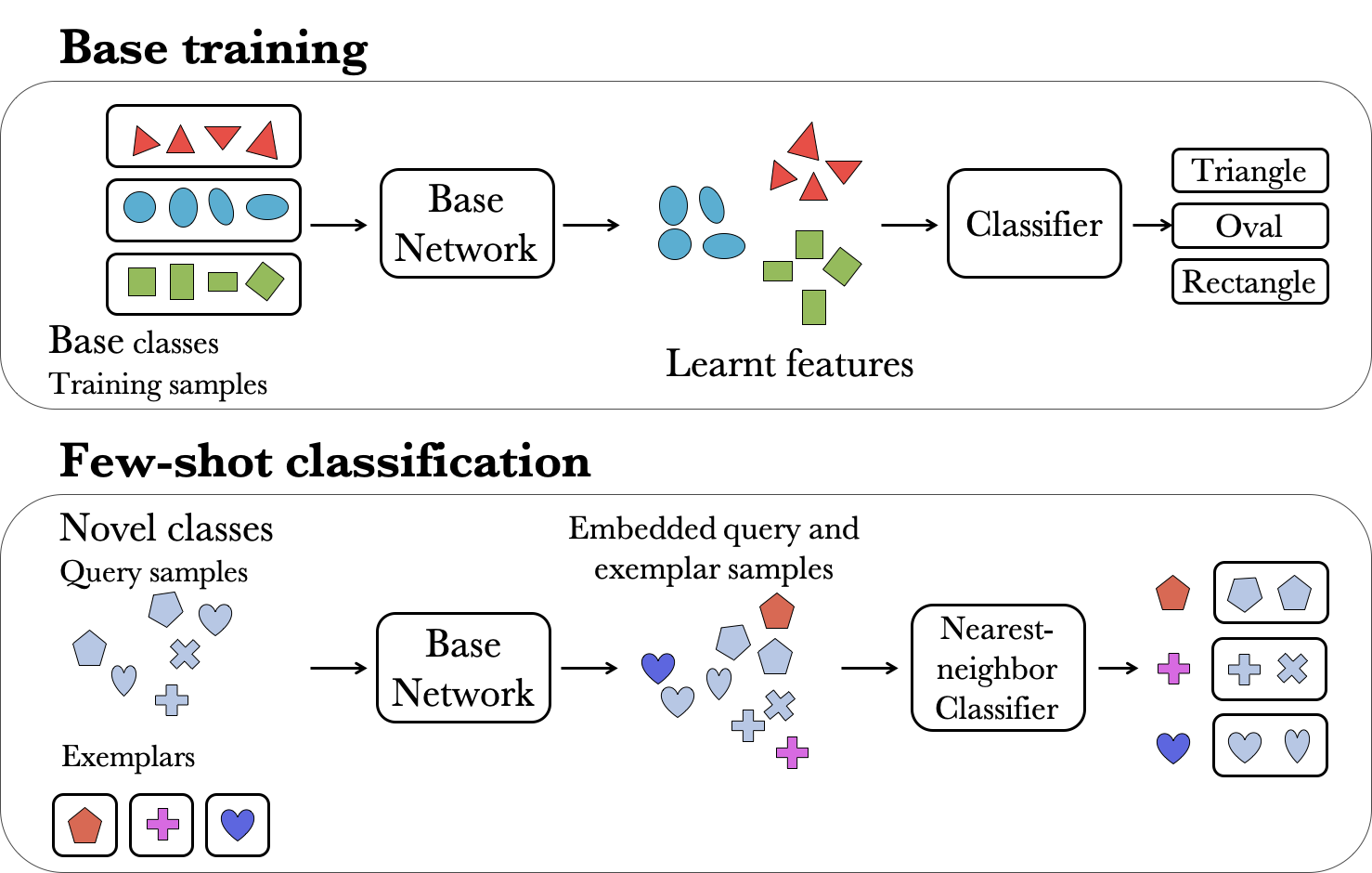
Figure 2: Illustration of the few-shot classification setup using nearest neighbors with pre-trained features.
Mini-IN6k dataset
To investigate a wide variety of base training datasets, we define the ImageNet-6K dataset as a subset of largest 6K classes from the ImageNet-22K dataset, excluding ImageNet-1K classes (resulting in more than 900 images for all the classes). For experiments on mini-ImageNet and CUB, we downsample the images to 84x84, leading to the MiniIN6K dataset. For CUB experiments, to avoid training on images from the CUB test set, we additionally looked for the most similar images to each of the 2953 images of CUB test set, and completely removed the 296 classes they belong to from any base training set to avoid any overlap between train and novel classes.
Defining new classes by splitting or grouping
A natural question is whether for a fixed set of images, different labels could be used to train a better feature extractor. To achieve such a new labelling, one can directly cluster images using for example the K-means algorithm. Another way is to use existing class labels to define new classes by splitting or merging them while maintaining a global structure.

Figure 3: a) Images from meta-classes obtained by grouping dataset classes using pre-trained features. Each line represents a meta-class. b) Examples of sub-classes obtained by splitting dataset classes using pre-trained features. Each column represents a sub-class.
Analysis
1. Importance of base data and its similarity to test data
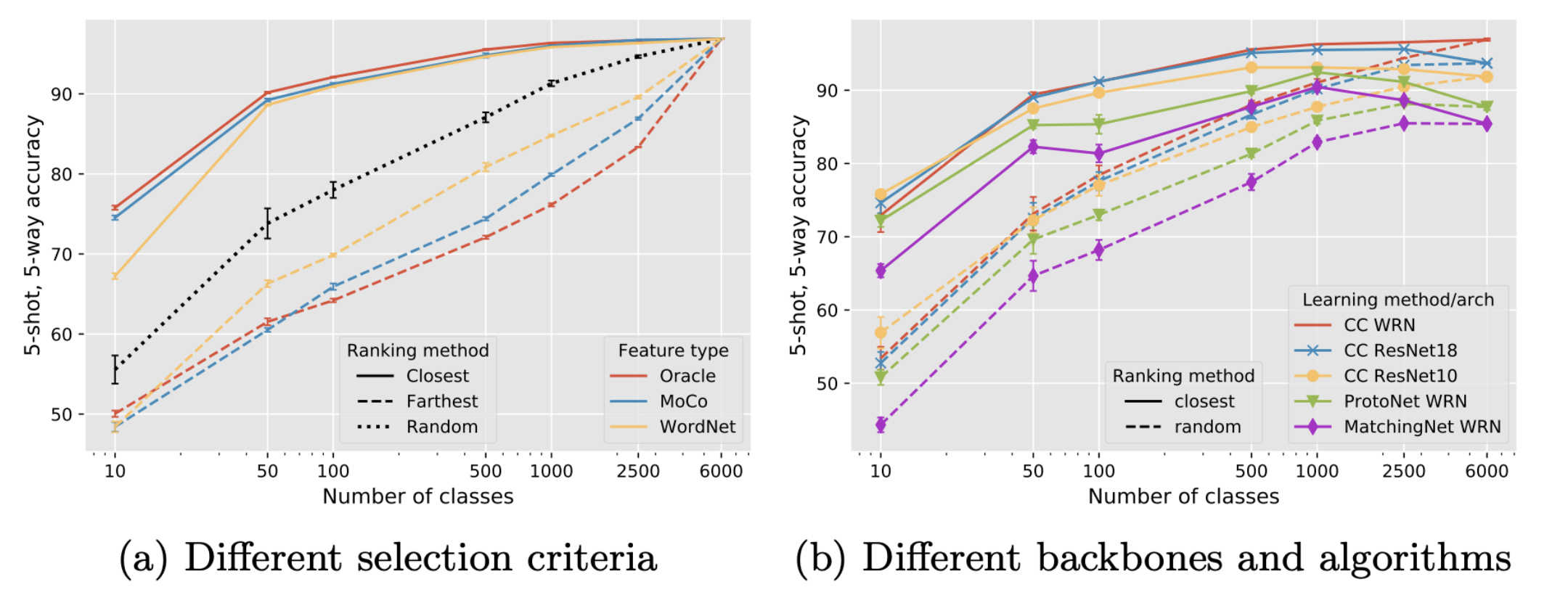
Figure 4: Five-shot accuracy on miniIN when sampling classes from miniIN-6K randomly or closest/farthest to the miniIN test set using 900 images per class. (a) Comparison between different class selection criteria for selecting classes closest or farthest from the test classes. (b) Comparison of results with different algorithms and backbones using oracle features to select closest classes.
2. Effect of the number of classes for a fixed number of annotations
An important practical question when building a base training dataset is the number of classes and images to annotate. The constraint often being the cost of the annotation process: we thus consider a fixed number of annotated images and explore the effect of the trade-off between the number of images per class and the number of classes.
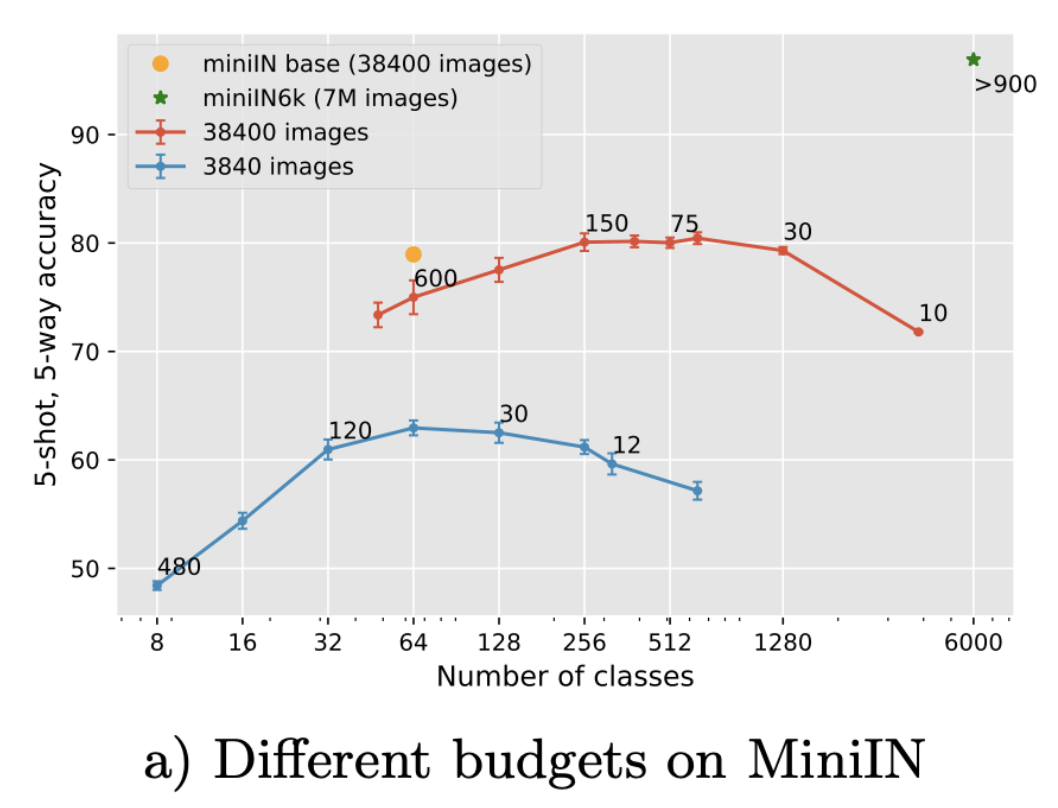
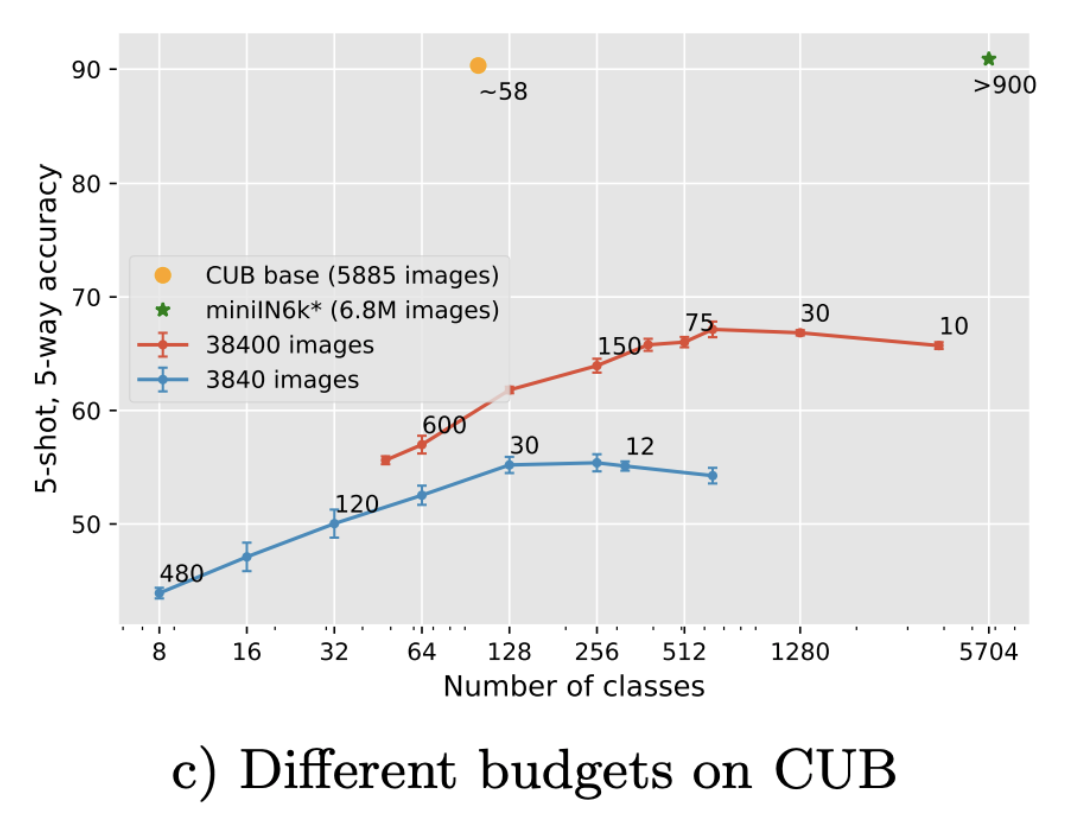
Figure 5: Trade-off between the number of classes and images per class for a fixed image budget. Each point is annotated with its corresponding number of images per class. We compare on miniImagenet (left) and CUB benchmarks (right).
The importance of this balance, and the fact that it does not necessarily correspond to the one used in the standard datasets is also important if one wants to pre-train features with limited resources.
3. Redefining classes by splitting and grouping
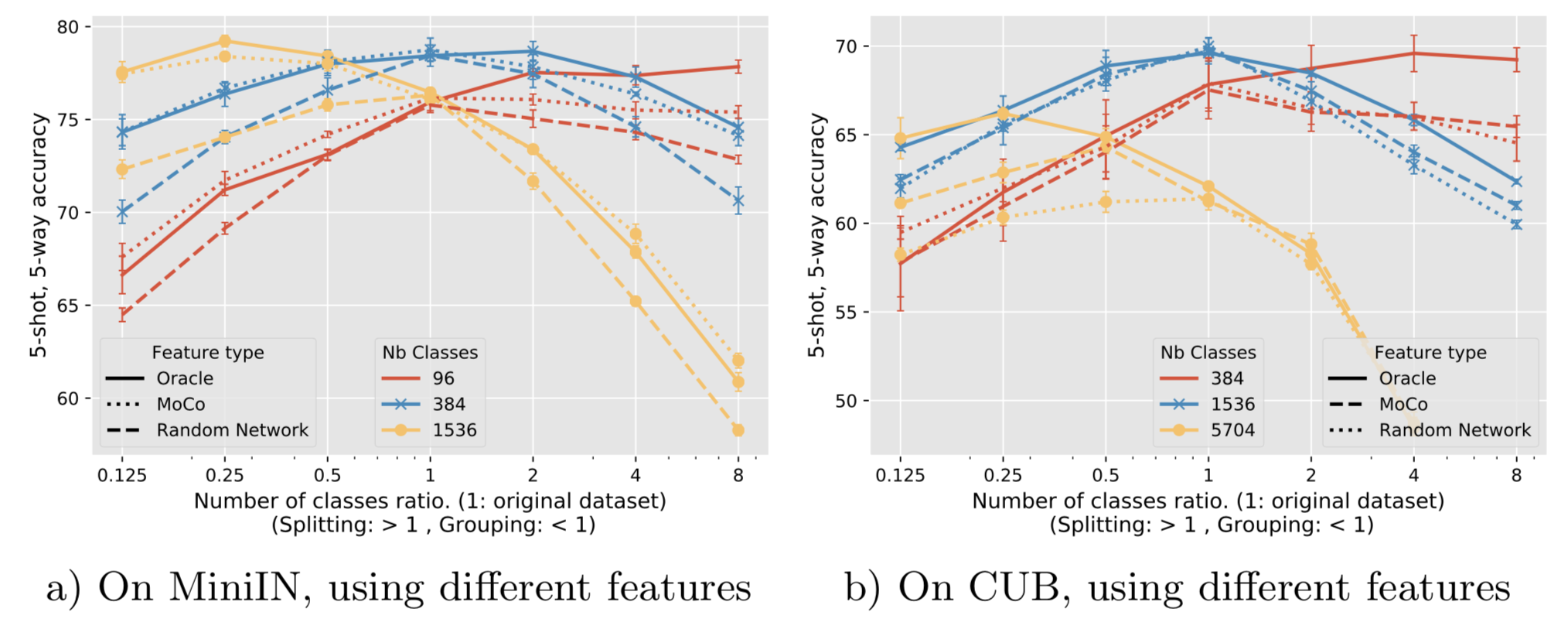
Figure 6: Impact of class Grouping or Splitting on few-shot accuracy on miniIN and CUB depending on the initial number of classes. Starting from different number of classes C in [96,384,1536], we group similar classes together into meta-classes or split them into sub-classes to obtain alpha x C ones. alpha in {1/8, 1/4, 1/2, 1, 2, 4, 8}, the x-axis.
Conclusion
Our empirical study outlines the key importance of the base training data in few-shot learning scenarios, with seemingly minor modifications of the base data resulting in large changes in performance, and carefully selected data leading to much better accuracy. We also show that few-shot performance can be improved by automatically relabelling an initial dataset by merging or splitting classes. We hope the analysis and insights that we present will:- impact dataset design for practical applications, e.g. given a fixed number of images to label, one should prioritize a large number of different classes and potentially use class grouping strategies using self-supervised features. In addition to base classes similar to test data, one should also prioritize simple classes, with moderate diversity.
- lead to new evaluations of few-shot learning algorithm, considering explicitly the influence of the base data training in the results: the current miniIN setting of 64 classes and 600 images per class is far from optimal for several approaches. Furthermore, the optimal trade-off between number of classes and number of images per class is different for different few-shot algorithms, suggesting taking into account different base data distributions in future few-shot evaluation benchmarks.
- inspire advances in few-shot learning, e.g. the design of practical approaches to adapt base training data automatically and efficiently to target few-shot tasks.
Long presentation video - 8 minutes
How to cite?
Citation
SBAI, Othman, COUPRIE, Camille, et AUBRY, Mathieu. Impact of base dataset design on few-shot image classification. ECCV 2020
Bibtex
@article{sbai2020impact,
title={Impact of base dataset design on few-shot image classification},
author={Sbai, Othman and Couprie, Camille and Aubry, Mathieu},
journal={ECCV},
year={2020}
}