
Abstract
Historical watermark recognition is a highly practical, yet unsolved challenge for archivists and historians. With a large number of well-defined classes, cluttered and noisy samples, different types of representations, both subtle differences between classes and high intra-class variation, historical watermarks are also challenging for pattern recognition. In this paper, overcoming the difficulty of data collection, we present a large public dataset with more than 6k new photographs, allowing for the first time to tackle at scale the scenarios of practical interest for scholars: one-shot instance recognition and cross-domain one-shot instance recognition amongst more than 16k fine-grained classes. We demonstrate that this new dataset is large enough to train modern deep learning approaches, and show that standard methods can be improved considerably by using mid-level deep features. More precisely, we design both a matching score and a feature fine-tuning strategy based on filtering local matches using spatial consistency. This consistency-based approach provides important performance boost compared to strong baselines. Our model achieves 55% top-1 accuracy on our very challenging 16,753-class one-shot cross-domain recognition task, each class described by a single drawing from the classic Briquet catalog. In addition to watermark classification, we show our approach provides promising results on fine-grained sketch-based image retrieval.
Video
| Video (5mins) |
What is watermark, why it is interesting to recognize?
A watermark was made by pressing a water-coated metal onto the paper during manufacturing. Watermark appears on almost all papers from XIV to XIXth century.
Recognizing watermark helps people (historians, archivists, auction houses, collectors) to locate and date papers, which is crucial to analyse and assess document.

Paper was made in a mold.
A small wire will leave a mark.

Paper with watermark.

Locating and dating paper.
Dataset
We release the watermark dataset composed of 4 parts targeting 4 different tasks:
Dataset A-classification
It contains 100 classes: 50 images / class for training and 10 images / class for validation. This part can be used to train a traditional classification neural network.

Different instances of the same watermark in our dataset A-classification.
Dataset A-one-shot
It contains 100 classes: 1 clean watermark as reference (without any text) + 2 query photographs in each class. This part can be used to evaluate one-shot recognition.

Dataset A-one-shot: 1 clean reference (without any text) + 2 query photographs (bottom)
Dataset B-cross-domain
It contains:
- 140 classes for training: 1 drawing watermark as reference + 1~7 normal photographs in each class.
- 100 classes for test: 1 drawing watermark as reference + 2 normal photographs in each class.
This part can be used to evaluate one-shot cross-domain recognition.

Dataset B-cross-domain: 1 drawing as reference (top) + 2 query normal photographs (bottom)
Briquet
It contains 16,753 classes, only 1 drawing in each class. The drawings in the Dataset B-cross-domain are included in Briquet. This part can be used to evaluate large scale one-shot cross-domain recognition.

Briquet: Examples of the 16,753 drawings from our subset of the Briquet catalog
Download dataset
Click here to download the whole dataset(~400M). It also includes the synthetic references that we mentioned in the paper.
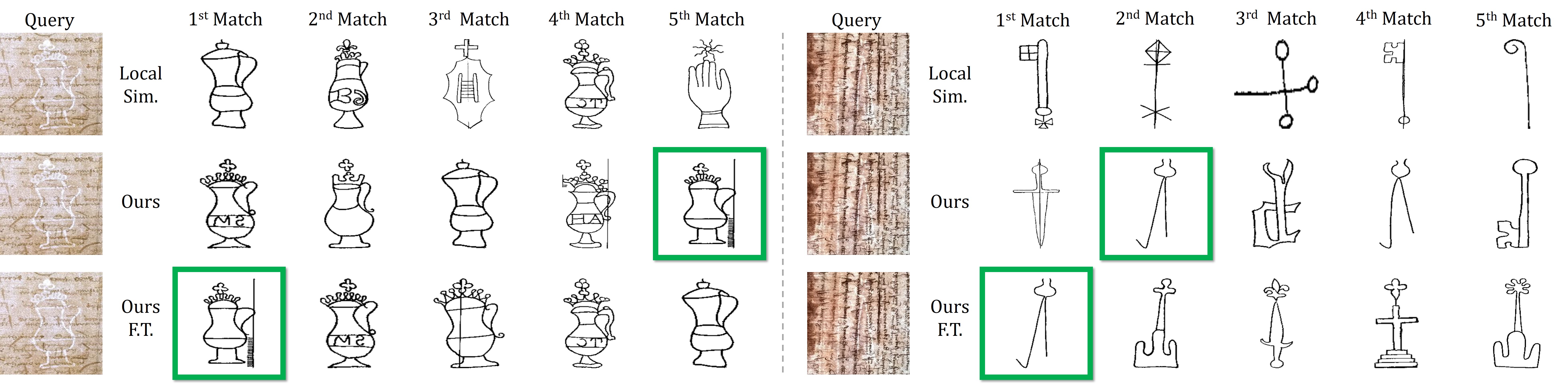
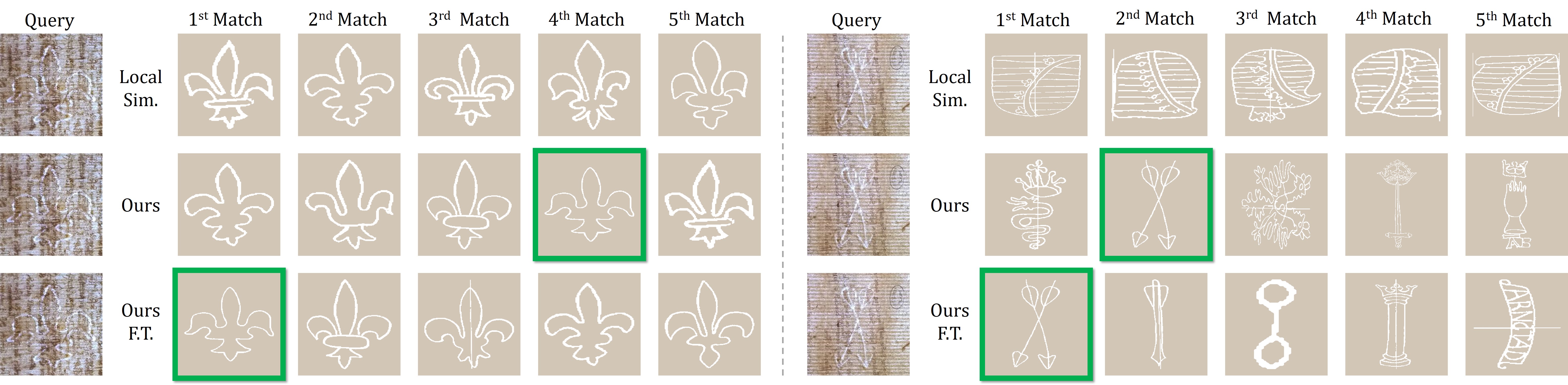
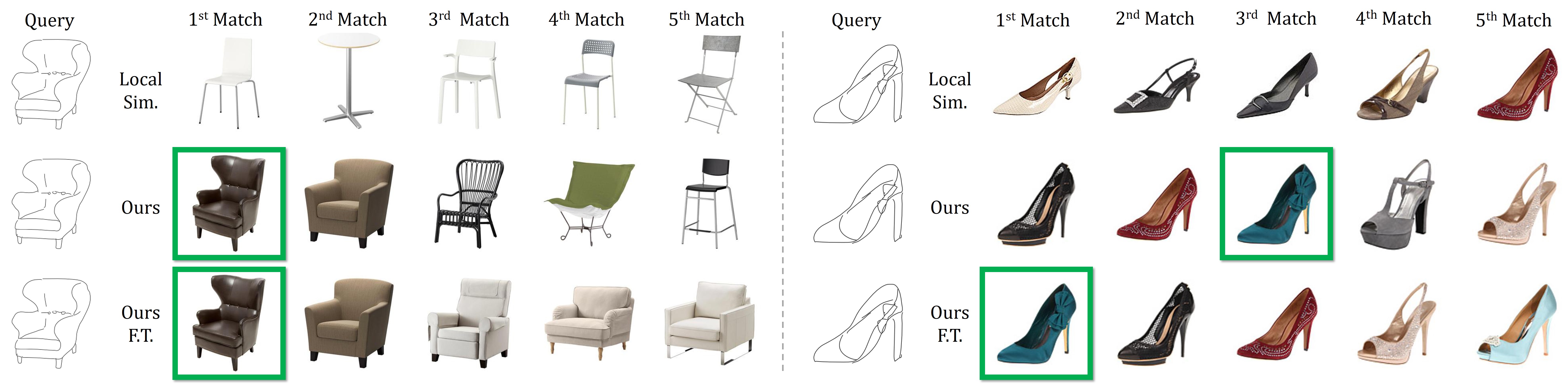
Visual Results
We show some top retrieval results here and provide more visual results in the following webpages:
- Our best top-5 retrieval results on Briquet (16,753-class, watermark), Shoes and Chairs dataset.
- Visual analysis of our score on Briquet: local contribution of different approaches, local score before and after fine-tuning
Resources




Web Application:
A Web Application for Watermark Recognition, Oumayma Bounou, Tom Monnier, Ilaria Pastrolin, Xi Shen, Christine Benevent, Marie-Françoise Limon-Bonnet, François Bougard, Mathieu Aubry, Marc Smith, Olivier Poncet, Pierre-Guillaume Raverdy
To cite our paper,
@inproceedings{shen2020watermark,
title={Large-Scale Historical Watermark Recognition: dataset and a new consistency-based approach},
author={Shen, Xi and Pastrolin, Ilaria and Bounou, Oumayma and Gidaris, Spyros and Smith, Marc and Poncet, Olivier and Aubry, Mathieu},
booktitle={ICPR},
year={2020}
}
Acknowledgment
This work was partly supported by ANR project EnHeritANR-17-CE23-0008 PSL Filigrane pour tous project and gifts from Adobe to Ecole des Ponts.