ENPC, Inria
Inria
ENPC
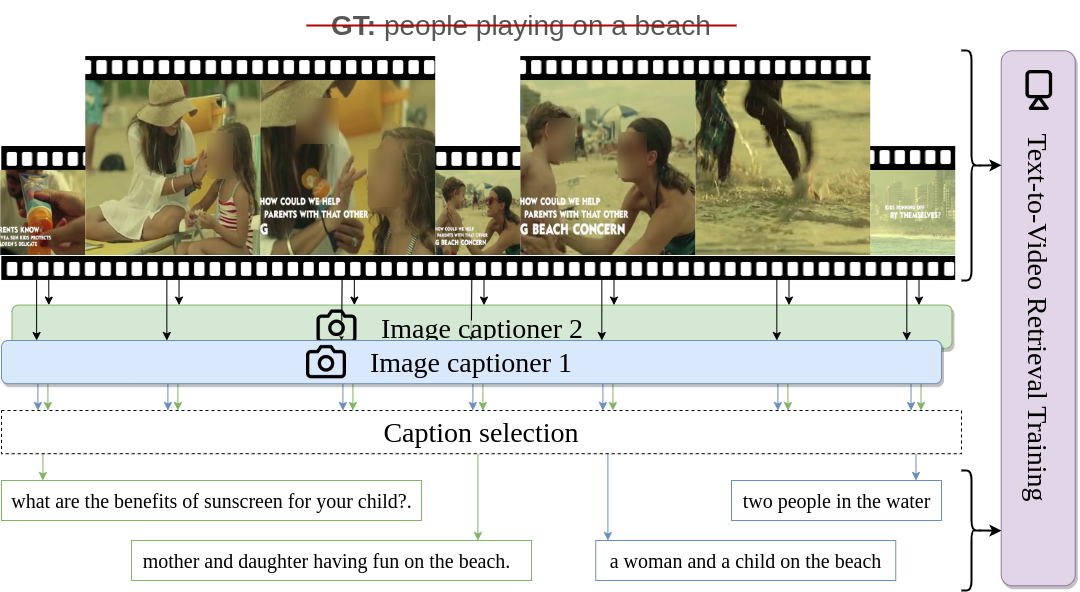
We describe a protocol to study text-to-video retrieval training with unlabeled videos, where we assume (i) no access to labels for any videos, i.e., no access to the set of ground-truth captions, but (ii) access to labeled images in the form of text. Using image expert models is a realistic scenario given that annotating images is cheaper therefore scalable, in contrast to expensive video labeling schemes. Recently, zero-shot image experts such as CLIP have established a new strong baseline for video understanding tasks. In this paper, we make use of this progress and instantiate the image experts from two types of models: a text-to-image retrieval model to provide an initial backbone, and image captioning models to provide supervision signal into unlabeled videos. We show that automatically labeling video frames with image captioning allows text-to-video retrieval training. This process adapts the features to the target domain at no manual annotation cost, consequently outperforming the strong zero-shot CLIP baseline. During training, we sample captions from multiple video frames that best match the visual content, and perform a temporal pooling over frame representations by scoring frames according to their relevance to each caption. We conduct extensive ablations to provide insights and demonstrate the effectiveness of this simple framework by outperforming the CLIP zero-shot baselines on text-to-video retrieval on three standard datasets, namely ActivityNet, MSR-VTT, and MSVD.
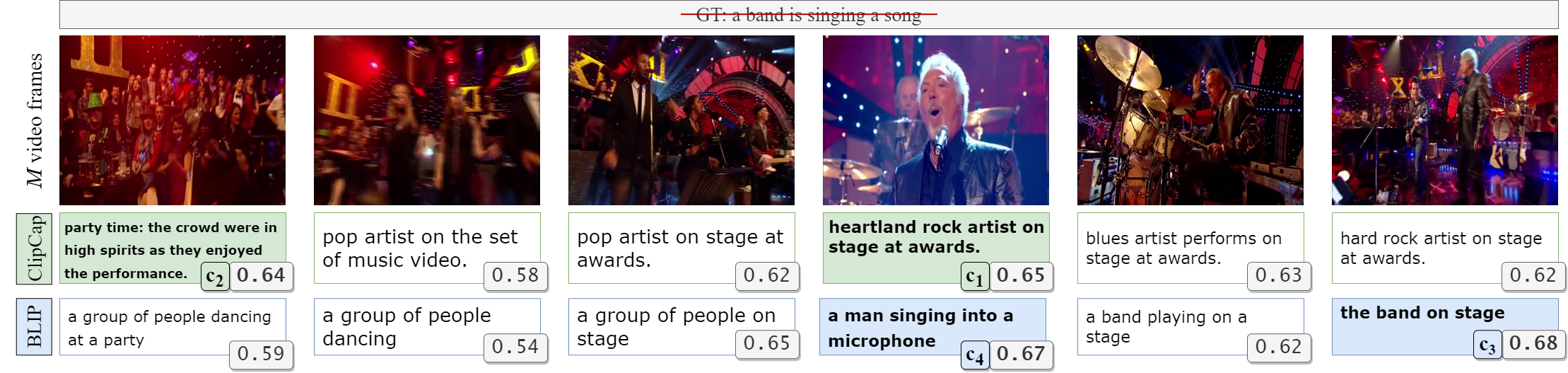
To select the best captions for a given video, we first extract image captions from both ClipCap and BLIP models for \(M\) number of frames. We then compute the CLIPScore (gray box), and finally select Top \(K=2\) captions for each captioner: \(c_1\) and \(c_2\) for ClipCap (highlighted in green), and \(c_3\) and \(c_4\) for BLIP (highlighted in blue).
For each dataset (ActivityNet, MSR-VTT, and MSVD) we provide the 4 best captions (2 ClipCap + 2 BLIP) per video.
@inproceedings{ventura23multicaps,
title = {Learning text-to-video
retrieval
from
image
captioning},
author = {Ventura, Lucas and Schmid,
Cordelia and
Varol,
G{\"u}l},
booktitle = {CVPR Workshop on Learning with
Limited Labelled Data for Image and Video
Understanding},
year = {2023}
}
@article{ventura24multicaps,
title = {Learning text-to-video
retrieval
from
image
captioning},
author = {Ventura, Lucas and Schmid,
Cordelia and
Varol,
G{\"u}l},
journal = {IJCV},
year = {2024},
doi={10.1007/s11263-024-02202-8}
}
This work was granted access to the HPC resources of IDRIS under the allocation 2022-AD011013060 made by GENCI. The authors would like to acknowledge the research gift from Google, the ANR project CorVis ANR-21-CE23-0003-01, and thank Elliot Vincent, Charles Raude, Georgy Ponimatkin, and Andrea Blazquez for their feedback.