Abstract¶
A large body of recent work targets semantically conditioned image generation. Most such methods focus on the narrower task of pose transfer and ignore the more challenging task of subject transfer that consists in not only transferring the pose but also the appearance and background. In this work, we introduce SCAM (Semantic Cross Attention Modulation), a system that encodes rich and diverse information in each semantic region of the image (including foreground and background), thus achieving precise generation with emphasis on fine details. This is enabled by the Semantic Attention Transformer Encoder that extracts multiple latent vectors for each semantic region, and the corresponding generator that exploits these multiple latents by using semantic cross attention modulation. It is trained only using a reconstruction setup, while subject transfer is performed at test time. Our analysis shows that our proposed architecture is successful at encoding the diversity of appearance in each semantic region. Extensive experiments on the iDesigner and CelebAMask-HD datasets show that SCAM outperforms SEAN and SPADE; moreover, it sets the new state of the art on subject transfer.
Pipeline¶
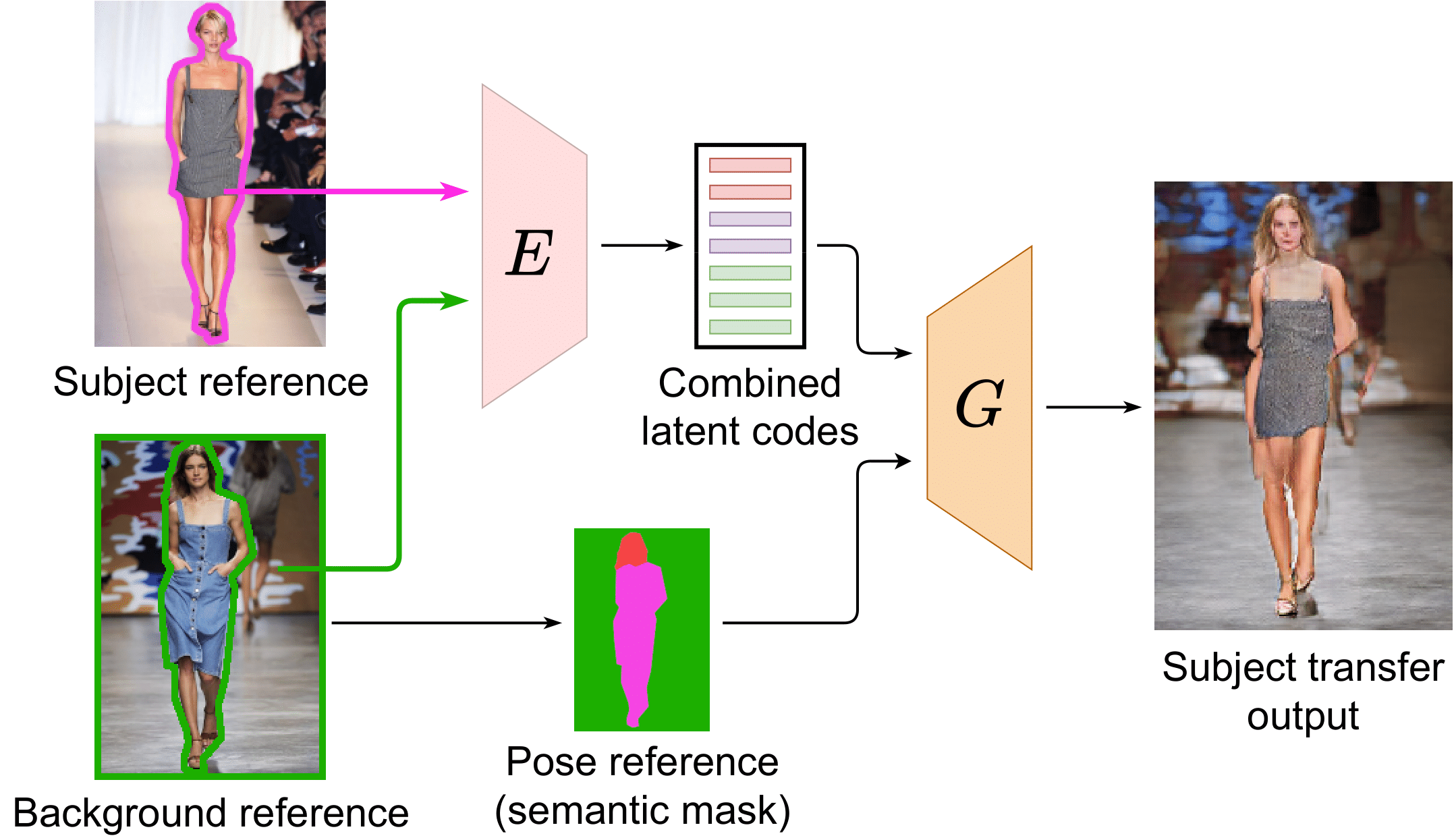
Architecture¶

Poster¶
Video¶
BibTex¶
@article{dufour2022scam,
title={SCAM! Transferring humans between images with Semantic Cross Attention Modulation},
author={Nicolas Dufour, David Picard, Vicky Kalogeiton},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022}
}
Acknowledgements¶
We would like to thank Dimitrios Papadopoulos, Monika Wysoczanska, Philippe Chiberre and Thibaut Issenhuth for proofreading. We would also like to thank Simon Ebel for the help with the video. This work was granted access to the HPC resources of IDRIS under the allocation 2021-AD011012630 made by GENCI and was supported by a DIM RFSI grant and ANR project TOSAI ANR-20-IADJ-0009.