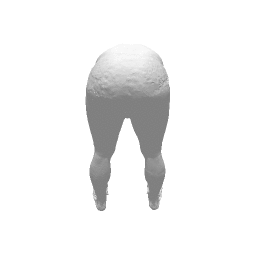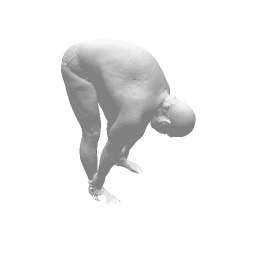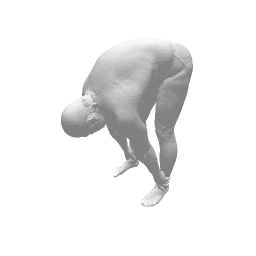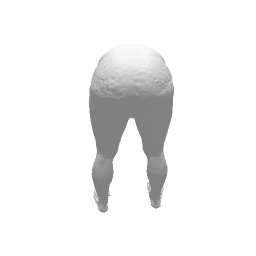
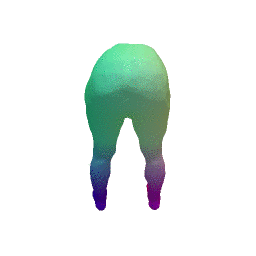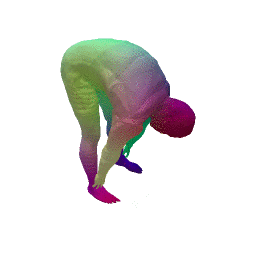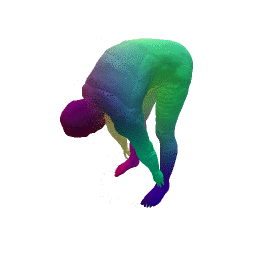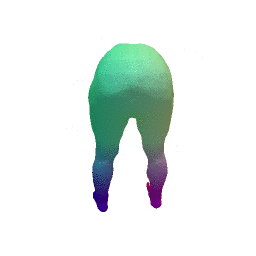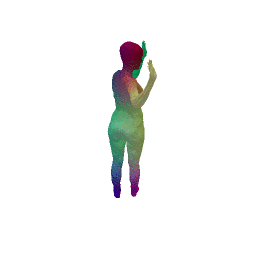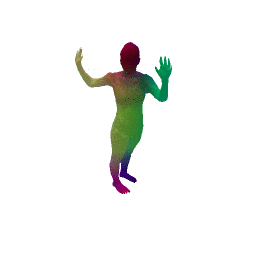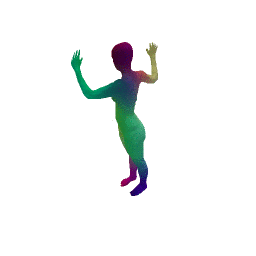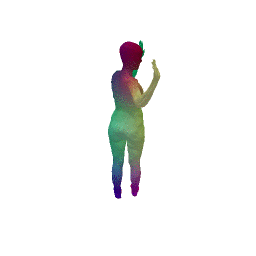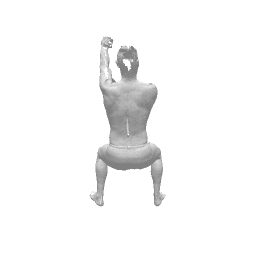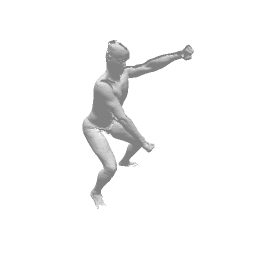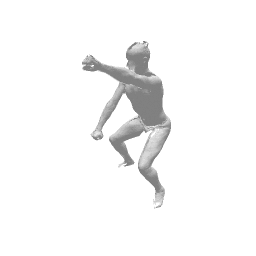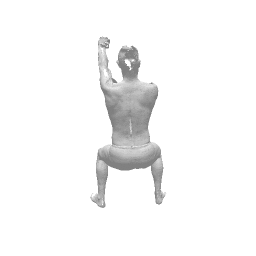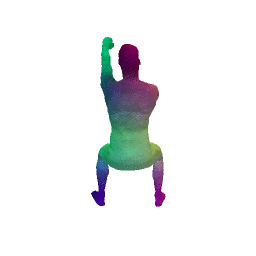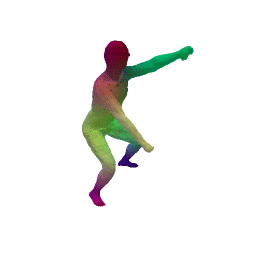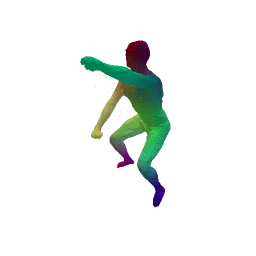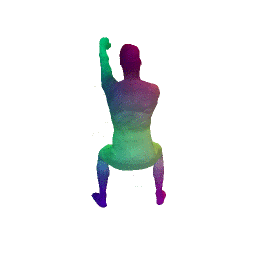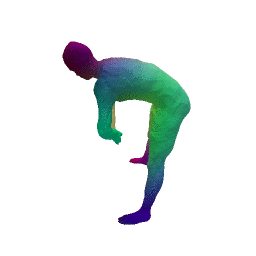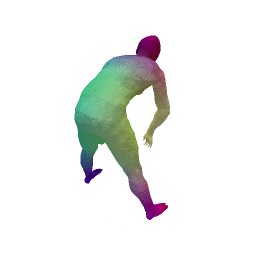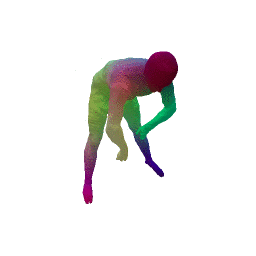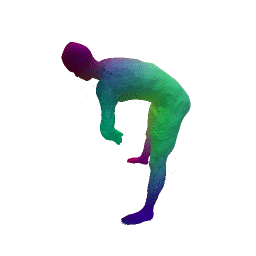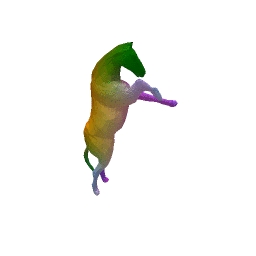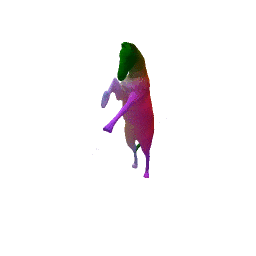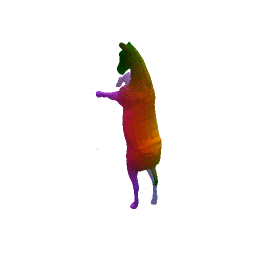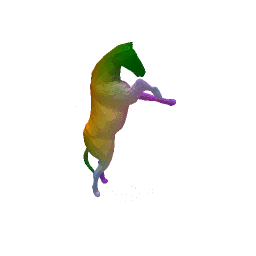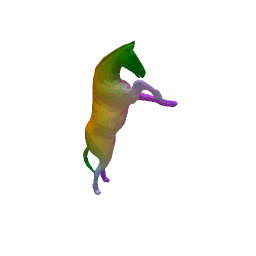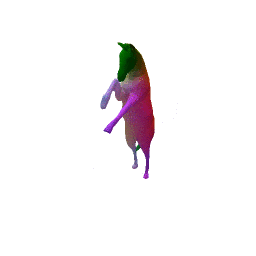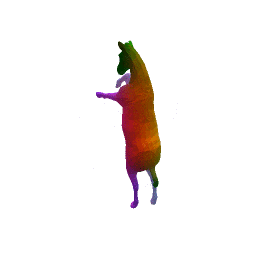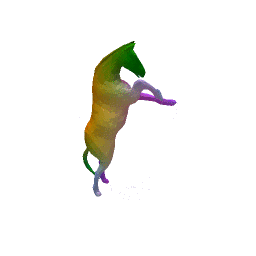Given two input shapes without correspondences (left) , the goal is to establish correspondences between them. To do so, we learn a smooth deformation transforming a template shape into the input shape. The two reconstructions (right) are naturally in correspondences, as they span from two different deformations of the same template.
We present a new deep learning approach for matching deformable shapes by introducing Shape Deformation Networks which jointly encode 3D shapes and correspondences. This is achieved by factoring the surface representation into (i) a template, that parameterizes the surface, and (ii) a learnt global feature vector that parameterizes the transformation of the template into the input surface. By predicting this feature for a new shape, we implicitly predict correspondences between this shape and the template. We show that these correspondences can be improved by an additional step which improves the shape feature by minimizing the Chamfer distance between the input and transformed template. We demonstrate that our simple approach improves on state-of-the-art results on the difficult FAUST-inter challenge, with an average correspondence error of 2.88cm. We show, on the TOSCA dataset, that our method is robust to many types of perturbations, and generalizes to non-human shapes. This robustness allows it to perform well on real unclean, meshes from the the SCAPE dataset.
Citing this work
If you find this work useful in your research, please consider citing :
@inproceedings{groueix2018b,
title = {3D-CODED : 3D Correspondences by Deep Deformation},
author={Groueix, Thibault and Fisher, Matthew and Kim, Vladimir G. and Russell, Bryan and Aubry, Mathieu},
booktitle = {ECCV},
year = {2018}
}
Full Pipeline on one shape
(a) Input(b) initial renconstruction(c) regression(d) final reconstruction
Our approach has three main steps. First, from the input shape (a ), a feed-forward pass through out encoder network generates an initial global shape descriptor ( b ). Second, we use gradient descent through our decoder network to refine this shape descriptor to improve the reconstruction quality ( c ). We can then use the template to correspond points between any two input shapes using their final reconstruction ( d ).
Robustness to perturbations
(a) Real scan with holes(b) Robust reconstruction(c) Real scan with holes(d) Robust reconstruction (e) Synthetic scan with synthetic holes(f) Robust reconstruction(g) Synthetic scan with synthetic noise(h) Robust reconstruction
Our method works on real scans with noise and potentially large holes. It is demonstrated on SCAPE dataset. Our method is robust to many types of perturbations namely, sampling rate, holes, topology, isometry, scaling, and added noise.