
Abstract
Motivated by the need of estimating the pose (viewpoint) of arbitrary objects in the wild, which is only covered by scarce and small datasets, we consider the challenging problem of class-agnostic 3D object pose estimation, with no 3D shape knowledge. The idea is to leverage features learned on seen classes to estimate the pose for classes that are unseen, yet that share similar geometries and canonical frames with seen classes. For this, we train a direct pose estimator in a class-agnostic way by sharing weights across all object classes, and we introduce a contrastive learning method that has three main ingredients: (i) the use of pre-trained, self-supervised, contrast-based features; (ii) pose-aware data augmentations; (iii) a pose-aware contrastive loss. We experimented on Pascal3D+ and ObjectNet3D, as well as Pix3D in a cross-dataset fashion, with both seen and unseen classes. We report state-of-the-art results, including against methods that use additional shape information, and also when we use detected bounding boxes.
Method
Direct Estimation Framework
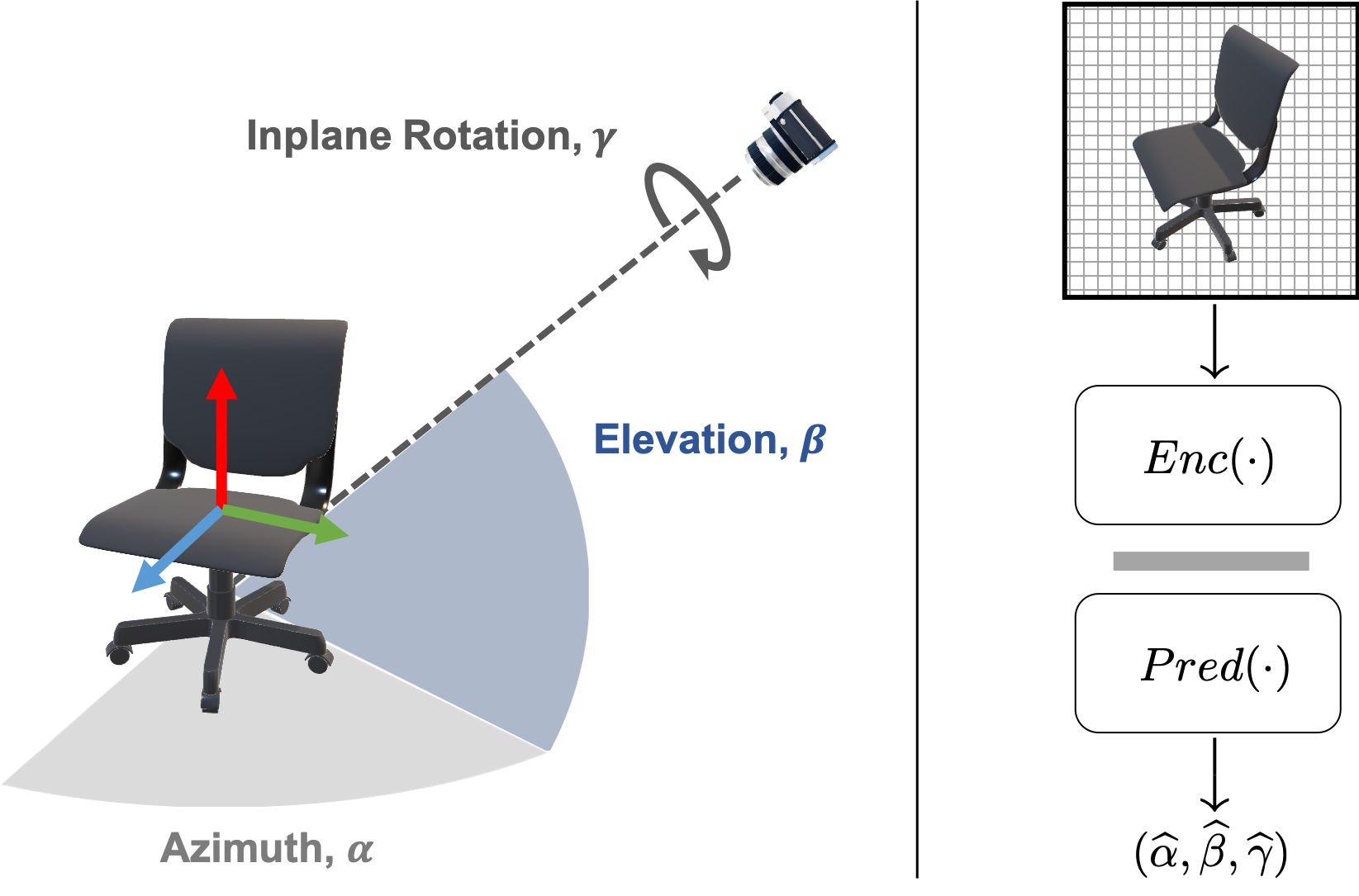
Pose Parameters (left): the viewpoint of an object consists of three Euler angles, namely Azimuth, Elevation and Inplane Rotation.
Network Architecture (right): from an image crop, the encoder produces an embedding, which is given to the predictor
to produce pose angles. The angle estimation loss is applied at the output of predictor while the pose-aware contrastive loss is applied at the output of encoder.
Pose-Aware Data Augmentations

Different types of Data Augmentations: while pose-invariant data augmentations do not alter the pose of the pictured object, pose-variant augmentations modify it and cannot be used as positives in pose-aware contrastive learning.
Pose-Aware Contrastive Loss


Pose-Invariant Contrastive Loss (left):
the network learns to pull together in feature space the query (e.g., chair) and a positive variant (e.g., flipped image), while pushing apart the query from negatives (different objects, e.g., sofa), ignoring pose information. Instead, we exclude flipped positives, whose pose actually differ from the query, and do not push apart negatives with similar poses (e.g., sofa).
Pose-Aware Contrastive Loss (right):
instead of treating all negatives equally, as for positive, we give more weight to negatives with a large rotation and less to those with a small rotation, regardless of their semantic class. Weights are repsented as the width of arrows.
Results
Viewpoint Estimation with Ground-Truth Box

Viewpoint Estimation with Object Detection

Qualitative Results on Pix3D. For each sample, we first plot the original image, then we visualize the pose prediction obtained from the ground-truth bounding box and the detected bounding box, respectively. The top two rows show results for seen classes that intersect with training data in Pascal3D+ (chair, sofa, table), while the bottom two rows show results for novel classes. Note that the 3D CAD object models are only used here for pose visualization purpose; our approach does not rely on them for object pose prediction.
Feature Space Visualization
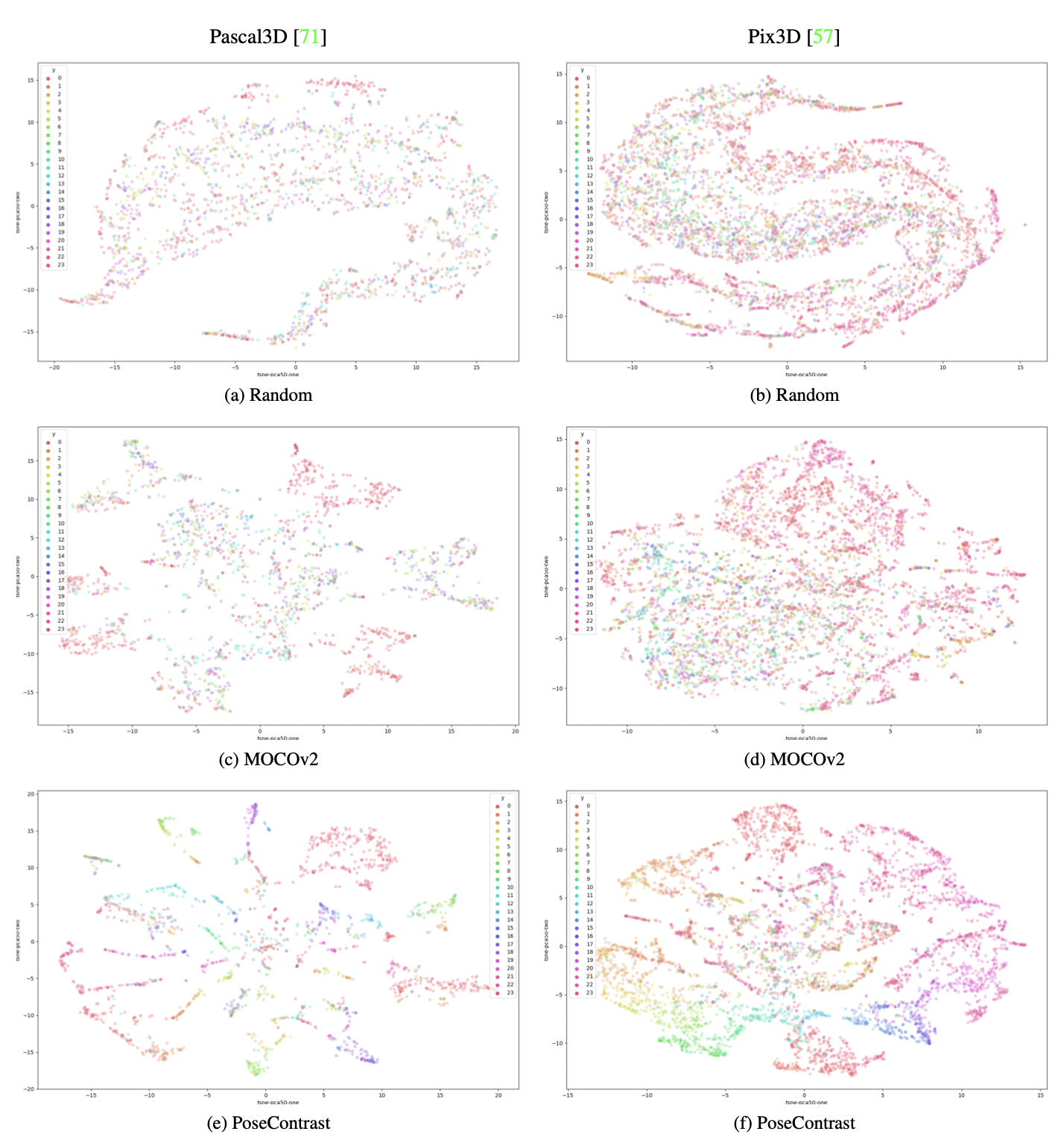
Visualization of the Learned Feature Space with Colored Azimuth Clusters. We visualize image features from the val set of Pascal3D+ (left) and Pix3D (right) by t-SNE (preceded by PCA) for three different ResNet-50 backbones: (a,b) randomly initialized network (top); (c,d) network pre-trained on ImageNet by MOCOv2 [6] (middle); and (e,f) network trained on Pascal3D+ with PoseContrast (bottom). We divide the 360 degrees of azimuth angle into 24 bins of 15◦ and use one color for each bin.
Paper, Code and Citation

To cite our paper,
@INPROCEEDINGS{Xiao2020PoseContrast,
author = {Yang Xiao and Yuming Du and Renaud Marlet},
title = {PoseContrast: Class-Agnostic Object Viewpoint Estimation in the Wild with Pose-Aware Contrastive Learning},
booktitle = {International Conference on 3D Vision (3DV)},
year = {2021}
}