
Abstract
We formalize concepts around geometric occlusion in 2D images (i.e., ignoring semantics), and propose a novel unified formulation of both occlusion boundaries and occlusion orientations via a pixel-pair occlusion relation. The former provides a way to generate large-scale accurate occlusion datasets while, based on the latter, we propose a novel method for task-independent pixel-level occlusion relationship estimation from single images. Experiments on a variety of datasets demonstrate that our method outperforms existing ones on this task. To further illustrate the value of our formulation, we also propose a new depth map refinement method that consistently improve the performance of state-of-the-art monocular depth estimation methods.
Method
For occlusion relationship estimation, we use a encoder-decoder structure (P2ORNet) which takes an RGB image as input and outputs neighbor pixel-pair occlusion relationships. By concatenating estimated occlusion relationships with coarse depth estimation, we use another encoder-decoder structure (DRNet) to achieve depth map refinement.
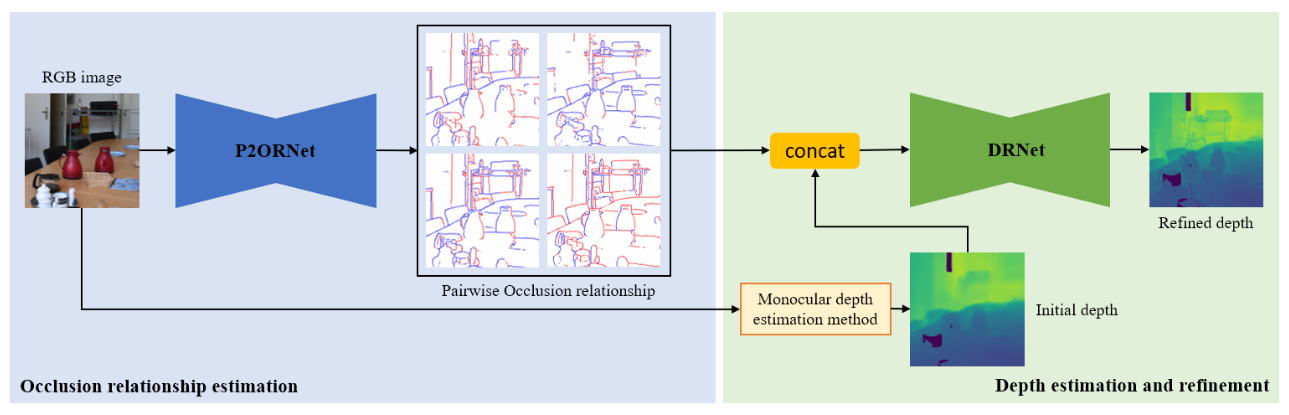
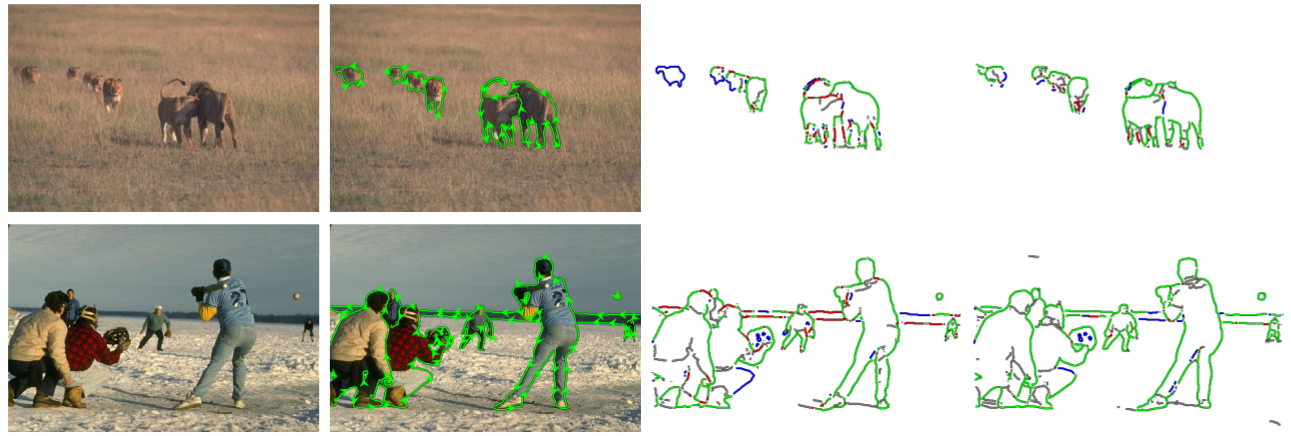
Visual Results

Paper, Code and Citation
To cite our paper,
@inproceedings{Qiu2020P2ORM,
title = {Pixel-{P}air Occlusion Relationship Map ({P2ORM}): Formulation, Inference \& Application},
author = {Xuchong Qiu and Yang Xiao and Chaohui Wang and Renaud Marlet},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}}