Given input as either a 2D image or a 3D point cloud (a), we automatically generate a corresponding 3D mesh (b) and its atlas parameterization (c). We can use the recovered mesh and atlas to apply texture to the output shape (d) as well as 3D print the results (e).
We introduce a method for learning to generate the surface of 3D shapes.
Our approach represents a 3D shape as a collection of parametric surface elements and, in contrast to methods generating voxel grids or point clouds, naturally infers a surface representation of the shape.
Beyond its novelty, our new shape generation framework, AtlasNet, comes with significant advantages, such as improved precision and generalization capabilities, and the possibility to generate a shape of arbitrary resolution without memory issues.
We demonstrate these benefits and compare to strong baselines on the ShapeNet benchmark for two applications: (i) auto-encoding shapes, and (ii) single-view reconstruction from a still image.
We also provide results showing its potential for other applications, such as morphing, parametrization, super-resolution, matching, and co-segmentation.
Video
Citing this work
If you find this work useful in your research, please consider citing :
@inproceedings{groueix2018,
title={{AtlasNet: A Papier-M\^ach\'e Approach to Learning 3D Surface Generation}},
author={Groueix, Thibault and Fisher, Matthew and Kim, Vladimir G. and Russell, Bryan and Aubry, Mathieu},
booktitle={Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year={2018}
}
Method
Traditionally, 3D reconstruction have been done using voxelised representations or point-clouds. In this work, we propose to directly learn a surface representation by deforming a set of surface elements, the "learnable parameterizations". (3D-R2N2).
(a) Baseline
(b) AtlasNet : 1 learnt parameterization
(b) AtlasNet : K learnt parameterization
Shape generation approaches. All methods take as input a latent shape representation (that can be learnt jointly with a reconstruction objective) and generate as output a set of points. (a) A baseline deep architecture would simply decode this latent representation into a set of points of a given size. (b) Our approach takes as additional input a 2D point sampled uniformly in the unit square and uses it to generate a single point on the surface. Our output is thus the continuous image of a planar surface, from which the topology can easily be transferred. In particular, we can easily infer a mesh of arbitrary resolution on the generated surface elements. (c) This strategy can be repeated multiple times to represent a 3D shape as the union of several surface elements.
AtlasNet can generate surfaces at arbitrary resolution (a). We observe a strong correspondence between the patches across different shapes (b). The learnable parameterizations are well-suited for distortion minimization (AQP TODO reference) and good UV parameterization are obtained.
Single View Reconstruction exemples and comparisojn with state-of-the-art
Single-view reconstruction comparison: From a 2D RGB image (a), 3D-R2N2 reconstructs a voxel-based 3D model (b), PointSetGen a point cloud based 3D model (c), and our AtlasNet a triangular mesh (d). pt
By interpoling the latent code of an autoencoder, we're able to make a smooth transition from one shape to another, which demonstrate the stability of our latent space (nice in full screen).
 Given input as either a 2D image or a 3D point cloud (a), we automatically generate a corresponding 3D mesh (b) and its atlas parameterization (c). We can use the recovered mesh and atlas to apply texture to the output shape (d) as well as 3D print the results (e).
Given input as either a 2D image or a 3D point cloud (a), we automatically generate a corresponding 3D mesh (b) and its atlas parameterization (c). We can use the recovered mesh and atlas to apply texture to the output shape (d) as well as 3D print the results (e).

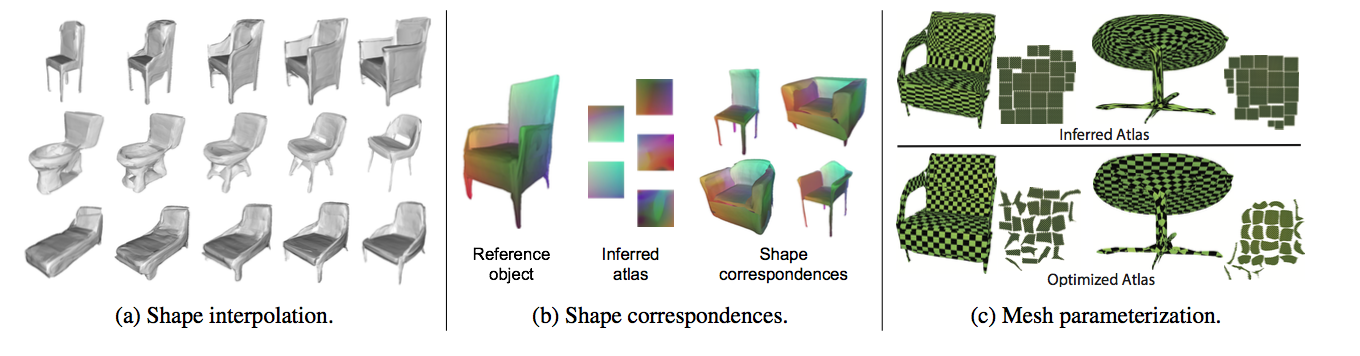 AtlasNet can generate surfaces at arbitrary resolution (a). We observe a strong correspondence between the patches across different shapes (b). The learnable parameterizations are well-suited for distortion minimization (AQP TODO reference) and good UV parameterization are obtained.
AtlasNet can generate surfaces at arbitrary resolution (a). We observe a strong correspondence between the patches across different shapes (b). The learnable parameterizations are well-suited for distortion minimization (AQP TODO reference) and good UV parameterization are obtained. Single-view reconstruction comparison: From a 2D RGB image (a), 3D-R2N2 reconstructs a voxel-based 3D model (b), PointSetGen a point cloud based 3D model (c), and our AtlasNet a triangular mesh (d). pt
Single-view reconstruction comparison: From a 2D RGB image (a), 3D-R2N2 reconstructs a voxel-based 3D model (b), PointSetGen a point cloud based 3D model (c), and our AtlasNet a triangular mesh (d). pt