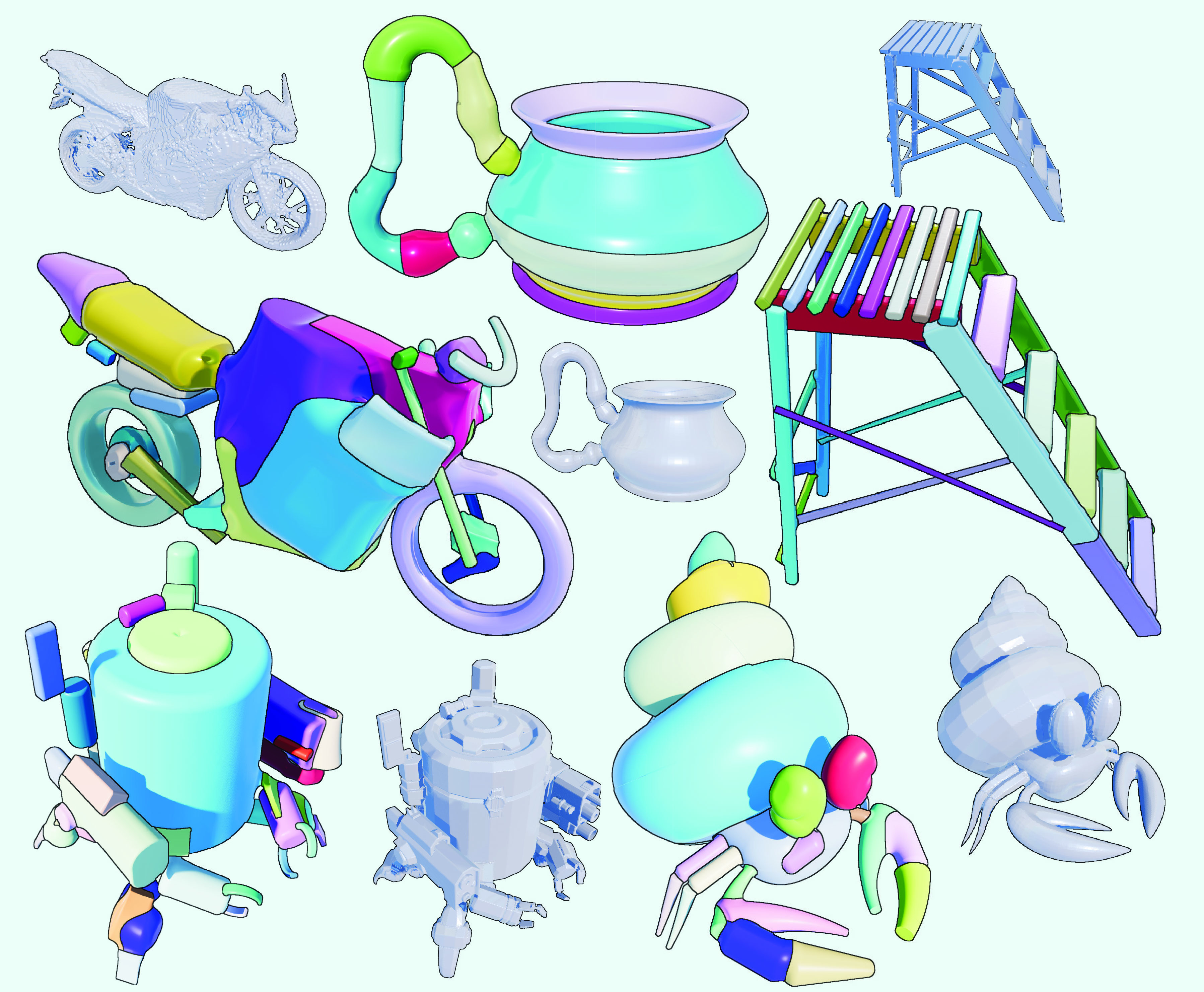
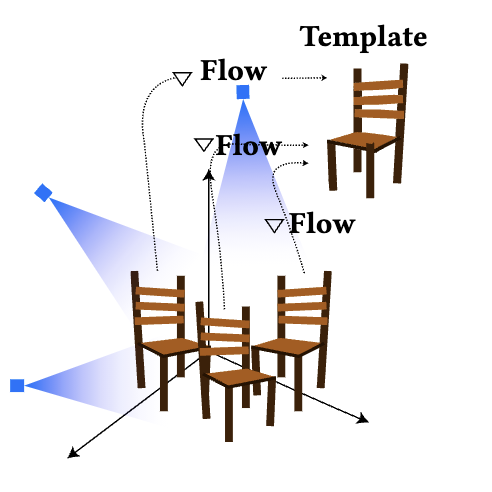
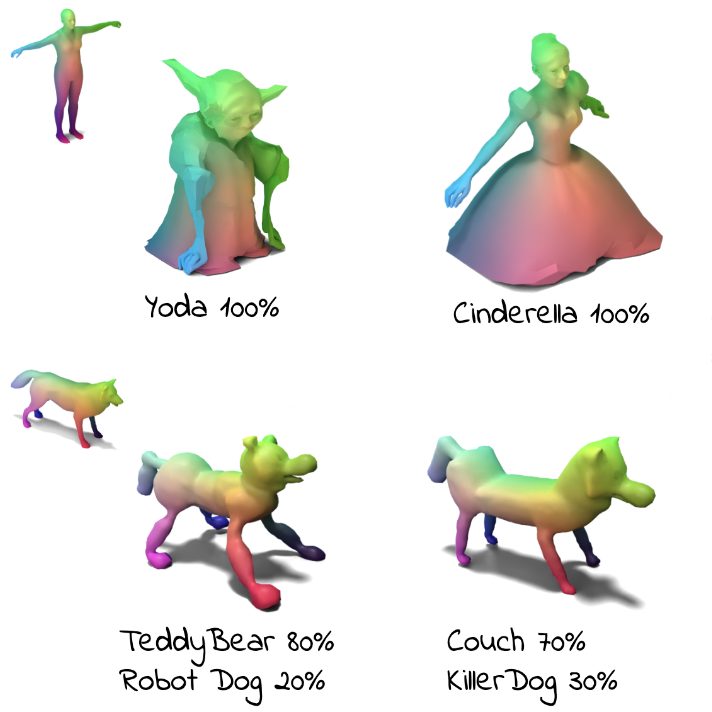
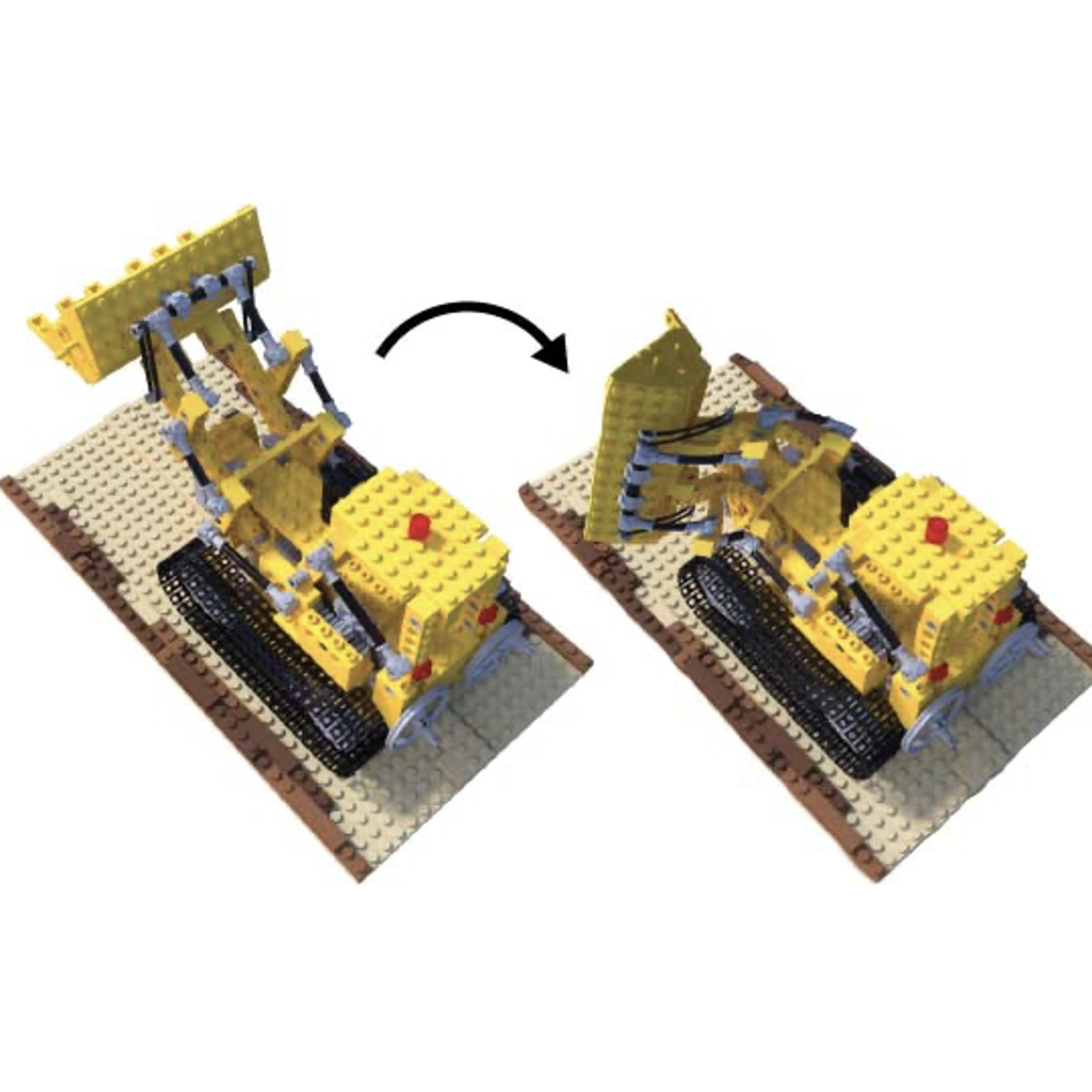
Thibault Groueix
Short bio: Thibault Groueix is an AI Research Scientist at META. His current focus is training large-scale models for 3D generative AI, towards building
world models. Previously, he conducted research at Adobe Research (2D Generative models), and Naver Labs Europe, and earned his PhD from the Imagine team of Ecole Nationale des Ponts et Chaussees,
advised by Mathieu Aubry. His thesis received the second place PhD awards from SIF and AFIA.
Pro-bono mentoring: I am happy to discuss anything related to your research career, especially if you belong to an underrepresented group in STEM. You can schedule a meeting here. From PhD applications, PhD life, to research internships, full-time jobs and so on. I studied in France, so I may have a hard time with questions specific to the US universities. You could also try reaching out to Matheus here about US-specific queries, or Julien.